ID de región
REGION_ID es un código abreviado que Google asigna en función de la región que seleccionas cuando creas la app. El código no corresponde a un país ni a una provincia, aunque algunos ID de región puedan parecer similares a los códigos de país y provincia que se suelen usar. En el caso de las apps creadas después de febrero de 2020, REGION_ID.r se incluye en las URL de App Engine. En el caso de las apps existentes creadas antes de esta fecha, el ID de región es opcional en la URL.
Obtén más información acerca de los ID de región.
El desarrollo de software consiste en realizar compensaciones, y los microservicios no son una excepción. Lo que ganas en la implementación de código y en la independencia de operación, lo pagas en sobrecarga de rendimiento. Esta sección proporciona algunas recomendaciones sobre los pasos que puedes seguir para minimizar este impacto.
Convertir operaciones CRUD en microservicios
Los microservicios son especialmente apropiados para las entidades a las que se accede con el patrón crear, recuperar, actualizar y borrar (CRUD). Cuando trabajas con tales entidades, normalmente usas solo una entidad a la vez, como un usuario, y normalmente realizas solo una de las acciones de CRUD a la vez. Por lo tanto, solo necesitas una llamada de microservicio para la operación. Busca entidades que tengan operaciones CRUD más un conjunto de métodos comerciales que podrían utilizarse en muchas partes de tu aplicación. Estas entidades son buenas candidatas para los microservicios.
Proporciona API en lotes
Además de las API de estilo CRUD, puedes proporcionar un buen rendimiento de microservicio para grupos de entidades mediante API en lotes. Por ejemplo, en lugar de solo exponer un método de la API de GET que recupera un solo usuario, proporciona una API que tome un conjunto de ID de usuario y muestre un diccionario de usuarios correspondientes, como se indica a continuación:
Solicitud:
/user-service/v1/?userId=ABC123&userId=DEF456&userId=GHI789Respuesta:
{
"ABC123": {
"userId": "ABC123",
"firstName": "Jake",
… },
"DEF456": {
"userId": "DEF456",
"firstName": "Sue",
… },
"GHI789": {
"userId": "GHI789",
"firstName": "Ted",
… }
}
El SDK de App Engine admite muchas API en lotes, como la capacidad de recuperar muchas entidades de Cloud Datastore a través de una sola RPC, por lo que el servicio de estos tipos de API en lotes puede ser muy eficiente.
Usa solicitudes asíncronas
A menudo, necesitarás interactuar con varios microservicios para redactar una respuesta.
Por ejemplo, es posible que necesites recuperar las preferencias de acceso del usuario y, también, los detalles de su empresa. Por lo general, estos datos no dependen uno del otro, y puedes recuperarlos en paralelo. La biblioteca Urlfetch del SDK de App Engine admite solicitudes asíncronas, lo que te permite llamar a microservicios en paralelo.
from google.appengine.api import urlfetch
preferences_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(preferences_rpc,
'https://preferences-service-dot-my-app.uc.r.appspot.com/preferences-service/v1/?userId=ABC123')
company_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(company_rpc,
'https://company-service-dot-my-app.uc.r.appspot.com/company-service/v3/?companyId=ACME')
### microservice requests are now occurring in parallel
try:
preferences_response = preferences_rpc.get_result() # blocks until response
if preferences_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
try:
company_response = company_rpc.get_result() # blocks until response
if company_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
El trabajo en paralelo a menudo es contrario a una buena estructura de código dado que, en una situación real, sueles usar una clase para encapsular los métodos de preferencias y otra clase a fin de encapsular los métodos de la empresa. Es difícil aprovechar las llamadas Urlfetch asíncronas sin romper este encapsulamiento. Existe una solución adecuada en el paquete NDB del SDK de App Engine para Python: Tasklets.
Los Tasklets te permiten mantener una buena encapsulación en tu código, al tiempo que ofrecen un mecanismo para lograr llamadas de microservicio en paralelo. Ten en cuenta que los tasklets usan objetos future en lugar de RPC, pero la idea es similar.
Usa la ruta más corta
Según la forma en que invoques Urlfetch, puedes generar que se usen diferentes infraestructuras y rutas. Para usar la ruta con mejor rendimiento, considera las siguientes recomendaciones:
- Usa
REGION_ID.r.appspot.com, en lugar de un dominio personalizado - Un dominio personalizado hace que se use una ruta diferente cuando el enrutamiento se realiza a través de la infraestructura de Google. Debido a que tus llamadas de microservicios son internas, es fácil de hacer y funciona mejor si usas
https://PROJECT_ID.REGION_ID.r.appspot.com. - Establece
follow_redirectscomoFalse - Establece
follow_redirects=Falsede forma explícita cuando llames aUrlfetch, ya que evita un servicio más pesado diseñado para seguir redireccionamientos. Tus extremos de API no deberían necesitar redireccionar los clientes porque son tus propios microservicios y solo deben mostrar respuestas de series HTTP 200, 400 y 500. - Utiliza servicios dentro de un proyecto mejor que sobre varios proyectos
- Hay buenas razones para usar varios proyectos cuando compilas una aplicación basada en microservicios, pero si tu objetivo principal es el rendimiento, usa servicios dentro de un solo proyecto. Los servicios de un proyecto se alojan en un mismo centro de datos y aunque la capacidad de procesamiento en la red de centro de datos interno de Google es excelente, las llamadas locales son más rápidas.
Evita la comunicación durante la aplicación de la seguridad
Usar mecanismos de seguridad que implican mucha comunicación en la autenticación de la API de llamada no es bueno para al rendimiento. Por ejemplo, si tu microservicio necesita validar un ticket de tu aplicación mediante una llamada a la aplicación, generarás una serie de idas y vueltas a fin de obtener tus datos.
Una implementación de OAuth2 puede amortizar este costo a lo largo del tiempo si se usan tokens de actualización y se almacena en caché un token de acceso entre las invocaciones Urlfetch. Sin embargo, si el token de acceso almacenado en caché se guarda en Memcache, necesitarás generar una sobrecarga de Memcache para recuperarlo. Para evitar esta sobrecarga, puedes almacenar en caché el token de acceso en una memoria de instancia, pero seguirás experimentando la actividad OAuth2 con frecuencia, ya que cada nueva instancia negocia un token de acceso; recuerda que las instancias de App Engine se activan y desactivan con frecuencia. Algunos híbridos de Memcache y la caché de instancia te ayudarán a mitigar este problema, pero aumentará la complejidad de tu solución.
Otro enfoque que funciona bien es compartir un token secreto entre los microservicios, por ejemplo, transmitido como un encabezado HTTP personalizado. En este enfoque, cada microservicio podría tener un token único para cada emisor. Por lo general, los secretos compartidos son una opción cuestionable para las implementaciones de seguridad, pero, como todos los microservicios están en la misma aplicación, se convierte en un problema menor dadas las ganancias de rendimiento. Con un secreto compartido, el microservicio solo necesita realizar una comparación de strings del secreto entrante con un diccionario en memoria, y la aplicación de la seguridad es muy ligera.
Si todos los microservicios están en App Engine, también puedes inspeccionar el encabezado X-Appengine-Inbound-Appid entrante.
La infraestructura Urlfetch agrega este encabezado cuando se realiza una solicitud a otro proyecto de App Engine y no lo puede establecer un tercero. Según los requisitos de seguridad, tus microservicios podrían inspeccionar este encabezado entrante para aplicar tu política de seguridad.
Realiza un seguimiento de las solicitudes de microservicios
A medida que compilas la aplicación basada en microservicios, comienzas a acumular una sobrecarga de llamadas sucesivas de Urlfetch. Cuando esto sucede, puedes usar Cloud Trace para comprender qué llamadas se están realizando y la ubicación de la sobrecarga. Es importante destacar que Cloud Trace también puede ayudar a identificar dónde se invocan los microservicios independientes en serie, a fin de que puedas refactorizar el código y realizar estas recuperaciones en paralelo.
Se activa una característica útil de Cloud Trace cuando usas varios servicios dentro de un solo proyecto. A medida que se realizan llamadas entre los servicios de microservicio en tu proyecto, Cloud Trace contrae todas las llamadas en un solo grafo de llamadas para permitirte visualizar la solicitud completa de extremo a extremo como un solo seguimiento.
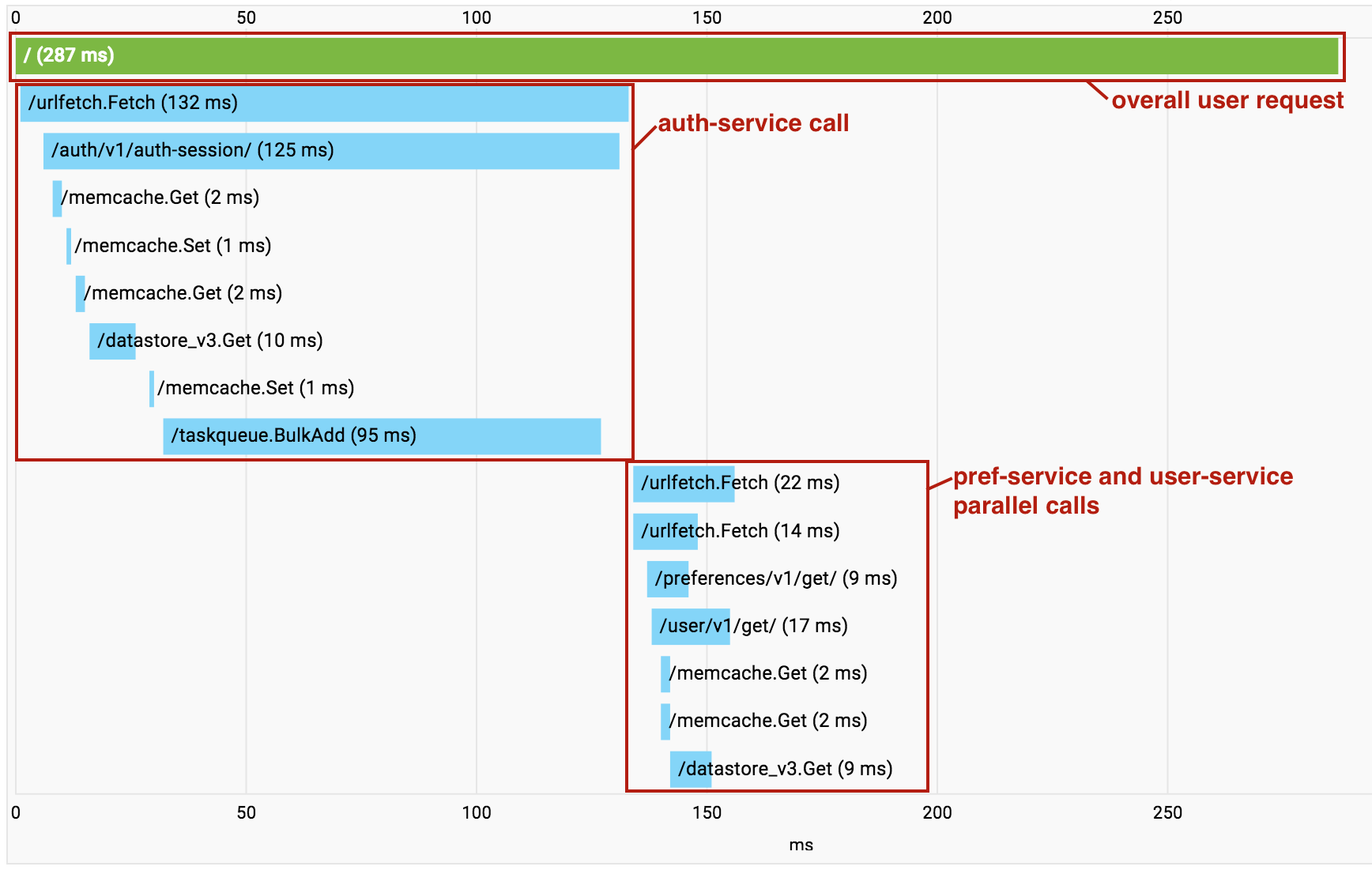
Ten en cuenta que en el ejemplo anterior, las llamadas a pref-service y user-service se realizan en paralelo mediante una Urlfetch asíncrona, por lo que las RPC parecen mezcladas en la visualización.
Sin embargo, esta sigue siendo una herramienta valiosa para diagnosticar la latencia.
Pasos siguientes
- Obtén una descripción general de la arquitectura de microservicios en App Engine.
- Entiende cómo crear y nombrar entornos de desarrollo, prueba, control de calidad, etapas de prueba y producción con microservicios en App Engine.
- Conoce las recomendaciones para diseñar API de comunicación entre microservicios.
- Aprende a migrar de una aplicación monolítica existente a una con microservicios.