Regions-ID
REGION_ID ist ein Abkürzungscode, den Google basierend auf der Region zuweist, die Sie beim Erstellen Ihrer Anwendung ausgewählt haben. Der Code bezieht sich nicht auf ein Land oder eine Provinz, auch wenn einige Regionen-IDs den häufig verwendeten Länder- und Provinzcodes ähneln. Bei Anwendungen, die nach Februar 2020 erstellt wurden, ist REGION_ID.r in App Engine-URLs enthalten. Bei vorhandenen Anwendungen, die vor diesem Datum erstellt wurden, ist die Regions-ID in der URL optional.
Hier finden Sie weitere Informationen zu Regions-IDs.
Erfahren Sie, wie Sie den Cloud Storage-Zugriff auf Ihre Python-Anwendung in App Engine auswählen und Dateien im Cloud Storage-Bucket erstellen, schreiben, lesen und auflisten.
In dieser Anleitung wird davon ausgegangen, dass Sie mit Python vertraut sind und Ihre Entwicklungsumgebung eingerichtet haben.
In diesem Beispiel wird ein Skript ausgeführt, das Daten an den Browser ausgibt. Das Skript zeigt die folgenden Funktionen der Cloud Storage-Clientbibliothek:
- Eine Datei erstellen und diese Datei in einen Bucket schreiben
- Die Datei lesen und ihre Metadaten abrufen
- Mehrere Dateien erstellen und anschließend aus dem Bucket auflisten
- Die Dateien auflisten, die gerade zum Bucket hinzugefügt wurden
- Diese Dateigruppe lesen
- Diese Dateigruppe löschen
Ziele
- Python-Projekt durchgehen und das erforderliche Layout und die erforderlichen Dateien aufrufen
- Code für die Verbindung mit Cloud Storage verstehen
- Code zum Erstellen, Schreiben, Lesen, Auflisten und Löschen von Dateien verstehen
- Code für Wiederholungen verstehen
- Anwendung auf Ihrem lokalen Entwicklungsserver erstellen und testen
- Anwendung für die Produktion in Google App Engine bereitstellen
Kosten
App Engine kann kostenlos genutzt werden. Wenn Ihre Nutzung von App Engine nicht das unter Kostenloses App Engine-Kontingent festgelegte Limit übersteigt, werden für diese Anleitung keine Gebühren erhoben.
Hinweise
Zum Ausführen dieses Beispiels benötigen Sie eine Projekt-ID, das gcloud-Befehlszeilentool und einen Cloud Storage-Bucket:
Erstellen Sie über die Google Cloud Console ein neues Console-Projekt oder rufen Sie die Projekt-ID eines vorhandenen Projekts ab:
Tipp: Rufen Sie mit dem Befehlszeilentool gcloud eine Liste der vorhandenen Projekt-IDs ab.
Installieren Sie die Google Cloud CLI und initialisieren Sie sie:
Cloud Console-Projekt-IDs mit gcloud auflisten
Führen Sie über die Befehlszeile folgenden Befehl aus:
gcloud projects list
Anleitungsprojekt klonen
Das Projekt klonen:
Klonen Sie die Clientbibliothek und die Beispielanwendung (Demo) auf Ihrem lokalen Computer.
git clone https://github.com/GoogleCloudPlatform/python-docs-samplesSie können auch das Beispiel als ZIP-Datei herunterladen und extrahieren.
Gehen Sie im geklonten oder heruntergeladenen Projekt zum entsprechenden Verzeichnis:
cd python-docs-samples/appengine/standard/storage/appengine-client
Abhängigkeiten installieren
Mit dem virtualenv-Tool können Sie eine saubere Python-Umgebung auf Ihrem System erstellen.
Bei der App Engine-Entwicklung trägt dies dazu bei, dass der von Ihnen lokal getestete Code der Umgebung ähnelt, in der Ihr Code bereitgestellt werden soll. Weitere Informationen finden Sie unter Drittanbieterbibliotheken verwenden.
virtualenv und die Abhängigkeiten des Beispiels installieren:
Mac OS/Linux
- Wenn virtualenv noch nicht installiert ist, installieren Sie es systemübergreifend mit dem Befehl
pip:sudo pip install virtualenv
- Erstellen Sie eine isolierte Python-Umgebung:
virtualenv envsource env/bin/activate - Wenn Sie sich nicht in dem Verzeichnis befinden, das den Beispielcode enthält, wechseln Sie zu dem Verzeichnis, das den Beispielcode
hello_worldenthält: Installieren Sie dann Abhängigkeiten:cd YOUR_SAMPLE_CODE_DIRpip install -t lib -r requirements.txt
Windows
Wenn Sie die Google Cloud CLI installiert haben, sollten Sie Python 2.7 bereits installiert haben, bei 64-Bit-Systemen in der Regel unter C:\python27_x64\. Führen Sie Ihre Python-Pakete mit PowerShell aus.
- Wechseln Sie zu Ihrer Installation von PowerShell.
- Klicken Sie mit der rechten Maustaste auf die Verknüpfung zu PowerShell und starten Sie diese als Administrator.
-
Versuchen Sie, den Befehl
pythonauszuführen. Wenn Python nicht gefunden wird, fügen Sie den Python-Ordner demPATHIhrer Umgebung hinzu.$env:Path += ";C:\python27_x64\"
- Wenn virtualenv noch nicht installiert ist, installieren Sie es systemübergreifend mit dem Befehl
pip:python -m pip install virtualenv
- Erstellen Sie eine isolierte Python-Umgebung.
python -m virtualenv env. env\Scripts\activate - Gehen Sie zu Ihrem Projektverzeichnis und installieren Sie die Abhängigkeiten: Wenn Sie sich nicht in dem Verzeichnis befinden, das den Beispielcode enthält, wechseln Sie zum Verzeichnis mit dem Beispielcode
hello_world. Installieren Sie dann Abhängigkeiten:cd YOUR_SAMPLE_CODE_DIRpython -m pip install -t lib -r requirements.txt
Der Beispielcode, den Sie geklont oder heruntergeladen haben, enthält bereits die Datei appengine_config.py. Diese muss App Engine anweisen, beim Laden der Abhängigkeiten sowohl lokal als auch bei der Bereitstellung den Ordner lib zu verwenden.
Lokal ausführen
Beispiel lokal ausführen:
Führen Sie die Anwendung im Projektunterverzeichnis
python-docs-samples/appengine/standard/storage/appengine-clientauf dem [lokalen Entwicklungsserver] aus:dev_appserver.py .Warten Sie auf die Bestätigungsmeldung, die in etwa so aussieht:
INFO 2016-04-12 21:33:35,446 api_server.py:205] Starting API server at: http://localhost:36884 INFO 2016-04-12 21:33:35,449 dispatcher.py:197] Starting module "default" running at: http://localhost:8080 INFO 2016-04-12 21:33:35,449 admin_server.py:116] Starting admin server at: http://localhost:8000Rufen Sie diese URL in Ihrem Browser auf:
Die Anwendung wird beim Laden der Seite ausgeführt. Über die Ausgabe des Browsers wird angezeigt, was ausgeführt wurde. Sie erhalten folgende Ausgabe:
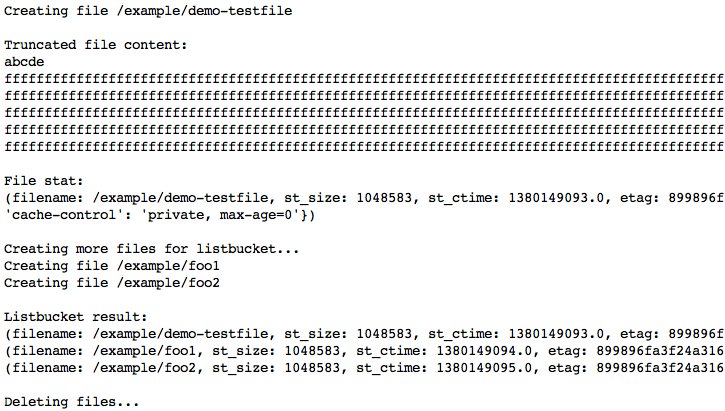
Stoppen Sie den Entwicklungsserver, indem Sie Strg+C drücken.
Anleitung zu app.yaml
Die Datei app.yaml enthält Details zur Anwendungskonfiguration:
Weitere Informationen zu den Konfigurationsoptionen in dieser Datei finden Sie in der app.yaml-Referenz.
Anleitung zu Importvorgängen
Die main.py-Datei enthält die typischen Importe für den Zugriff auf Cloud Storage über die Clientbibliothek:
Sie benötigen das os-Modul und die app_identity API, um den Namen des Standard-Buckets zur Laufzeit abzurufen. Sie benötigen diesen Bucket-Namen für den Cloud Storage-Zugriff.
Im Beispiel wird auch das Web-Framework webapp2 verwendet.
Cloud Storage-Bucket angeben
Bevor Sie Vorgänge in Cloud Storage ausführen können, müssen Sie den Bucket-Namen angeben. Der einfachste Weg dafür ist die Verwendung des Standard-Buckets für Ihr Projekt. Dieser kann folgendermaßen abgerufen werden:
Datei in Cloud Storage schreiben
Im folgenden Beispiel wird gezeigt, wie in den Bucket geschrieben wird:
Beachten Sie Folgendes: Im Beispiel werden beim Aufrufen von open für das Öffnen der Datei zum Schreiben bestimmte Cloud Storage-Header angegeben, die benutzerdefinierte Metadaten für die Datei festlegen. Diese Metadaten können mit cloudstorage.stat abgerufen werden. Eine Liste der unterstützten Header finden Sie in der Referenz zu cloudstorage.open.
Beachten Sie auch, dass der x-goog-acl-Header nicht festgelegt wird. Das bedeutet, dass beim Schreiben in den Bucket die standardmäßige Cloud Storage-ACL für öffentlichen Lesezugriff auf das Objekt angewendet wird.
Achten Sie außerdem auf den Aufruf von close für die Datei, nachdem der Schreibvorgang abgeschlossen ist. Ohne diesen Aufruf wird die Datei nicht in Cloud Storage geschrieben. Nach dem Aufrufen von close ist das Anhängen an die Datei nicht mehr möglich. Wenn Sie eine Datei ändern möchten, müssen Sie die Datei im Schreibmodus noch einmal öffnen. Dadurch wird sie überschrieben und nicht angehängt.
Datei aus Cloud Storage lesen
Im folgenden Beispiel wird gezeigt, wie eine Datei aus dem Bucket gelesen wird:
Das Beispiel zeigt, wie ausgewählte Zeilen aus der gelesenen Datei, in diesem Fall die Eingangszeile und die letzten 1.000 Zeilen, mit seek angezeigt werden.
Beachten Sie, dass im obigen Code kein Modus angegeben ist, wenn die Datei zum Lesen geöffnet wird. Der Standardwert für open ist der schreibgeschützte Modus.
Bucket-Inhalt auflisten
Der Beispielcode zeigt, wie Sie mit den marker-Parametern und max_keys einen Bucket mit einer großen Anzahl an Dateien durchgehen, um eine Liste der Inhalte des Buckets zu prüfen:
Beachten Sie, dass der vollständige Dateiname als eine Zeichenfolge ohne Verzeichnistrennzeichen angezeigt wird.
Wenn Sie die Datei mit der besser erkennbaren Verzeichnishierarchie darstellen möchten, legen Sie für den Parameter delimiter das gewünschte Verzeichnistrennzeichen fest.
Dateien löschen
Im Codebeispiel wird das Löschen von Dateien dargestellt, in diesem Fall das Löschen aller Dateien, die während des Ausführens der Anwendung hinzugefügt wurden. In Ihrem Code würden Sie nicht so vorgehen, dies soll in diesem Beispiel nur zur Bereinigung dienen.
Das Beispiel bereitstellen
Das Beispiel in App Engine bereitstellen und ausführen:
Laden Sie die Beispielanwendung hoch, indem Sie im Verzeichnis
python-docs-samples/appengine/standard/storage/appengine-client, in dem sich die Dateiapp.yamlbefindet, den folgenden Befehl ausführen:gcloud app deployOptionale Flags:
- Verwenden Sie das Flag
--project, um eine andere Console-Projekt-ID als jene anzugeben, die Sie in der gcloud CLI als Standard initialisiert haben. Beispiel:--project [YOUR_PROJECT_ID] - Verwenden Sie das Flag
-v, um eine Versions-ID festzulegen, andernfalls wird eine neue erstellt. Beispiel:-v [YOUR_VERSION_ID]
Tipp: Wenn Sie die Versions-ID einer zuvor hochgeladenen Anwendung angeben, überschreibt Ihre Bereitstellung die vorhandene Version in App Engine. Dies ist nicht immer wünschenswert, insbesondere wenn die Version in App Engine Traffic bereitstellt. Das können Sie vermeiden, wenn Sie die neue Version der Anwendung mit einer anderen Versions-ID bereitstellen und dann den Traffic auf diese Version verschieben. Weitere Informationen zum Verschieben von Traffic finden Sie unter Traffic-Aufteilung.
- Verwenden Sie das Flag
Nachdem der Bereitstellungsprozess abgeschlossen ist, können Sie die Anwendung unter
https://PROJECT_ID.REGION_ID.r.appspot.commit folgendem Befehl aufrufen:gcloud app browseDie
demo-Anwendung wird beim Laden der Seite genau wie bei der lokalen Ausführung ausgeführt. Jetzt schreibt und liest die Anwendung jedoch tatsächlich aus dem Cloud Storage-Bucket.
Weitere Informationen zum Bereitstellen der Anwendung über die Befehlszeile finden Sie unter Python 2-Anwendung bereitstellen.
Nächste Schritte
- Auswahl zentraler Cloud Storage-Konzepte
- Funktionsreferenz der Cloud Storage-Clientbibliothek
- RetryParams-Klassenreferenz
- Referenz zur Fehlerbehandlung
- Referenzarchitekturen, Diagramme, Anleitungen und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center