The examples on this page show some hypothetical scenarios using fleets that illustrate some of the concepts and best practices from our guides. Before reading this guide, you should be familiar with the concepts in Introducing fleets and Fleet requirements and best practices.
Example 1: Fleets with production, staging, and development resources
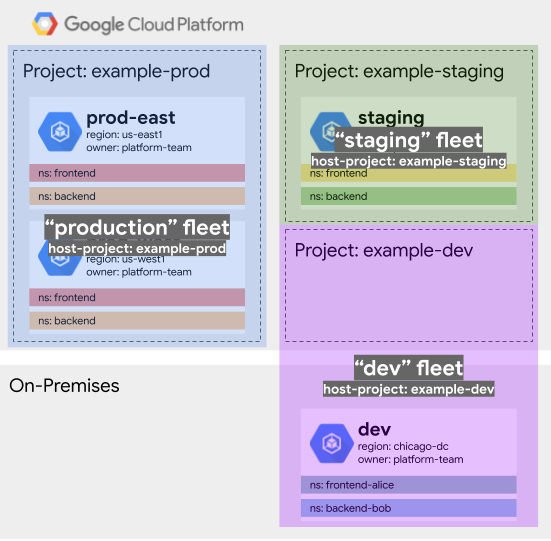
In this first example, there are four clusters. Two clusters are for production
(in two regions for redundancy), one is for staging and testing, and the final
one is for development. All of the clusters are owned and administered
centrally by a platform team. In this simple example, there are two services:
frontend and backend. However, more complex scenarios might have a
greater number of both services and clusters.

Approach 1: Separate fleets for production, staging, and development
One possible approach to leveraging fleets is to create separate fleets for production, staging, and development resources.
To do this, we create three separate fleet host projects and either place
resources in those projects, or in the case of our on-premises development
cluster, register the cluster to the example-dev project. We did not have to
address many of the namespace sameness and service sameness concerns due to the
granularity in this example, but we did ensure that the prod-east and
prod-west clusters' namespaces were well-normalized.
The advantage of this approach is that we have very strong isolation between each of the fleets. The main drawback of this approach is that we need to administer three different fleets, which makes it harder to achieve consistency between production, staging, and development. For development teams, it is also harder to develop against staged services.
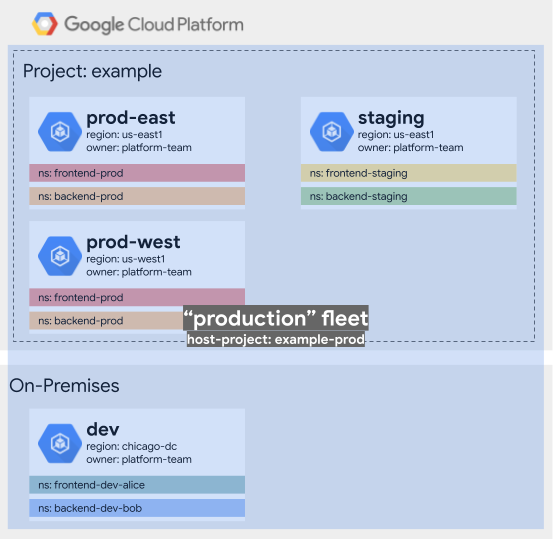
Approach 2: One fleet for all resources
In this approach, we create a single fleet for all resources.
To do this, we can leave the resources in the example project, and create the
fleet in that project. We could have separated our production and staging
resources by placing them in other fleet host projects and leveraging
Shared VPC, but we chose not to for simplicity
in this example.
With this approach, we need to ensure that our namespaces and services are
normalized throughout the fleet. For example, we rename our generic frontend
to frontend-prod and frontend-staging in the production and staging clusters
respectively. Finally, while we could keep the original names for our
development namespaces, we provide clearer names (like frontend-dev-alice) to
indicate that they are development namespaces.
With this approach, we're trading off isolation for ease of management. We're relying on service mesh authorization to prevent unwanted service-to-service communication, but we can easily administer the overall system with the one fleet. This arrangement enables us to apply policies across all resources, which can give us confidence that development looks and feels very close to production.
Approach 3: Separate fleets for production and non-production
In this approach, we take a middle ground that combines the staging and development resources together into a non-production fleet while placing production in a separate fleet.
To do this, we create two fleet host projects, one for production and one for
non-production. We also place our resources directly into those projects, with
the dev cluster on-premises registered into our non-production fleet. We
need to normalize the namespaces and services between our staging and
development resources to provide clarity; for example, we rename frontend to
frontend-staging in the staging cluster.
The advantage here is that production is well-isolated from non-production. For
example, we can enable development services to talk to staging services, so
developer Alice's frontend can talk to a staged backend while she's
developing her service.

Summary
Each of the approaches outlined in Example 1 is valid. Which one your organization chooses depends on isolation versus consistency (and ease of management); in other words, how much isolation is needed between different resource types versus how much consistency is needed across them. More consistency is easier to achieve with fewer fleets. The third approach is offered as a possible compromise, keeping production completely isolated while giving developers the ability to work against staged services.
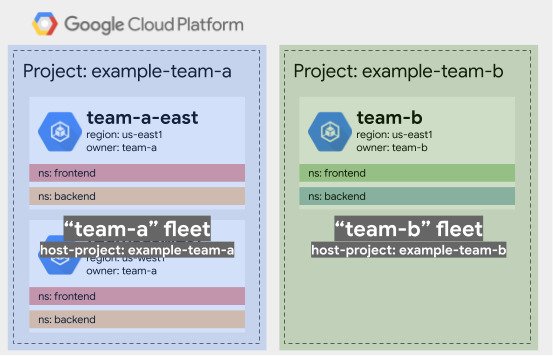
Example 2: Fleets with different resource owners
For this example, we have two teams, team-a and team-b. These teams own and
administer their own clusters, and both have used namespaces frontend and
backend for the services that they produce. However, neither team-a's
frontend nor backend is actually the same as team-b's. The two teams want to
create a service mesh so that their services can interact.

Without some intervention, there is no way to make these clusters part of the
same mesh. One good starting point is to transfer ownership of the clusters to a
centralized platform team to establish trust between them. Alternatively, if
team-a and team-b trust each other, they can also coordinate to form this trust.
The next step is to normalize the namespace usage so that frontend and
backend are no longer overloaded in these two teams' clusters. After this is
done, they can establish a single fleet over all of the resources and create
their service mesh.

If this level of trust cannot be established, team-a and team-b should form two separate fleets that use two different fleet host projects. The drawback with this approach is that they now need to leverage mesh federation, which is harder to administer than a single mesh. The benefit is that neither team needs to normalize their deployed namespaces and services, and only explicit and specifically authorized communication is possible.