This page describes high availability options in GKE on VMware.
Core functionality
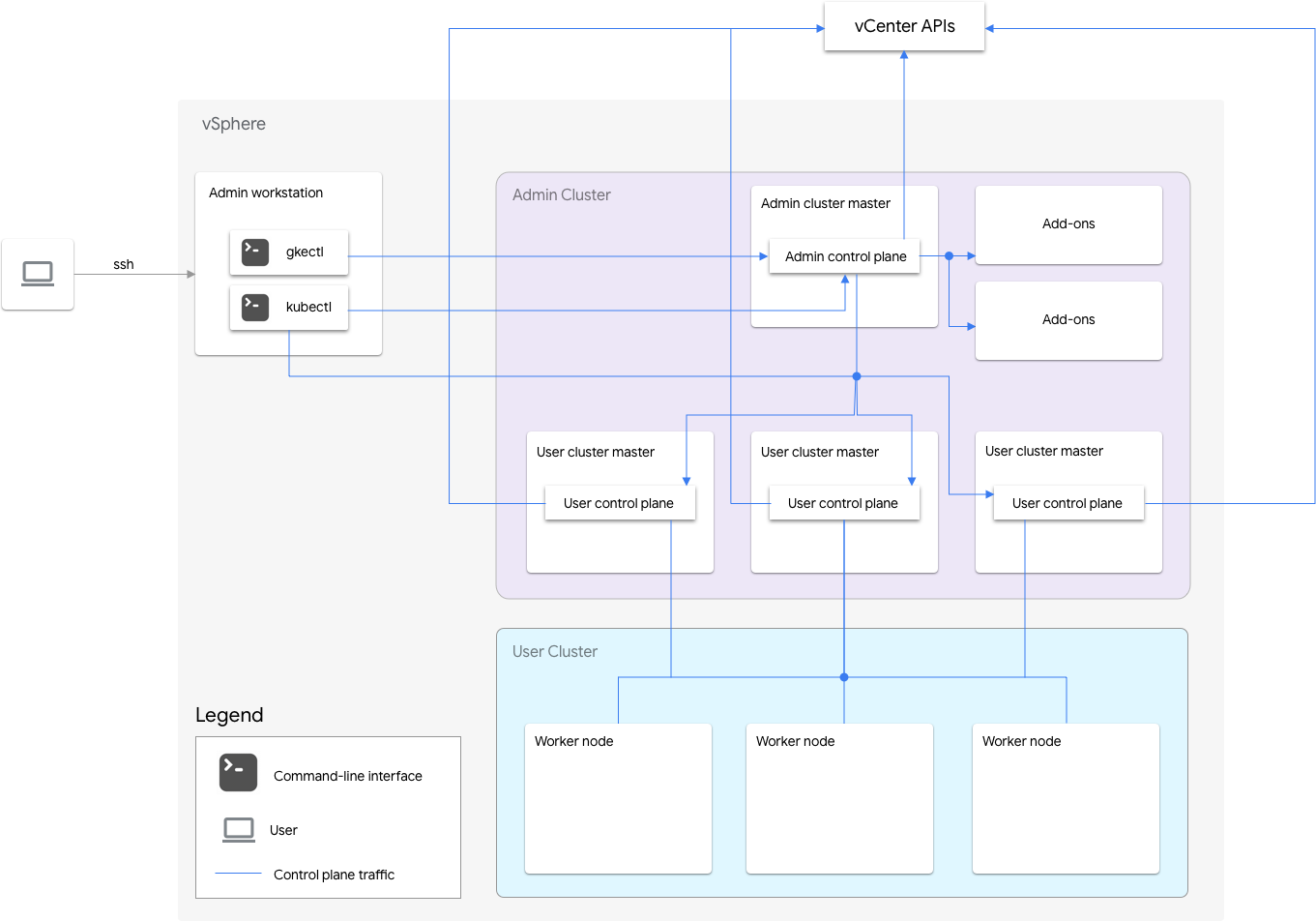
GKE on VMware includes an admin cluster and one or more user clusters.
The admin cluster manages the lifecycle of the user clusters, including user cluster creation, updates, upgrades, and deletion. In the admin cluster, the admin master manages the admin worker nodes, which include user masters (nodes running the control plane of the managed user clusters) and addon nodes (nodes running the addon components supporting the admin cluster's functionality).
For each user cluster, the admin cluster has one non-HA node or three HA nodes that run the control plane. The control plane includes the Kubernetes API server, the Kubernetes scheduler, the Kubernetes controller manager, and several critical controllers for the user cluster.
The user cluster's control plane availability is critical to workload operations such as workload creation, scaling up and down, and termination. In other words, a control plane outage does not interfere with the running workloads, but the existing workloads lose management capabilities from the Kubernetes API server if its control plane is absent.
Containerized workloads and services are deployed in the user cluster worker nodes. Any single worker node should not be critical to application availability as long as the application is deployed with redundant pods scheduled across multiple worker nodes.
Enabling high availability
vSphere and GKE on VMware provide a number of features that contribute to high availability (HA).
vSphere HA and vMotion
We recommend enabling the following two features in the vCenter cluster that hosts your GKE on VMware clusters:
These features enhance availability and recovery in case an ESXi host fails.
vCenter HA uses multiple ESXi hosts configured as a cluster to provide rapid
recovery from outages and cost-effective HA for applications
running in virtual machines. We recommend that you provision your vCenter
cluster with extra hosts and
enable vSphere HA Host Monitoring
with Host Failure Response set to Restart VMs. Your VMs can then be
automatically restarted on other available hosts in case of an ESXi host failure.
vMotion allows zero-downtime live migration of VMs from one ESXi host to another. For planned host maintenance, you can use vMotion live migration to avoid application downtime entirely and ensure business continuity.
Admin cluster
GKE on VMware supports creating high-availability (HA) admin clusters. A HA admin cluster has three nodes that run control-plane components. For information on requirements and limitations, see High-availability admin cluster.
Note that unavailability of the admin cluster control plane doesn't affect existing user cluster functionality or any workloads running in user clusters.
There are two add-on nodes in an admin cluster. If one is down, the other one
can still serve the admin cluster operations. For redundancy,
GKE on VMware spreads critical add-on Services, such as kube-dns,
across both of the add-on nodes.
If you set antiAffinityGroups.enabled to true in the admin cluster
configuration file, GKE on VMware automatically creates
vSphere DRS
anti-affinity rules for the add-on nodes, which causes them to be spread across
two physical hosts for HA.
User cluster
You can enable HA for a user cluster by setting masterNode.replicas to 3 in
the user cluster configuration file. If the user cluster has
Controlplane V2
enabled (recommended), the 3 control plane nodes run in the user cluster.
Legacy HA kubeception user clusters
run the three control plane nodes in the admin cluster. Each control plane
node also runs an etcd replica. The user cluster continues to work
as long as there is one control plane running and an etcd quorum. An etcd
quorum requires that two of the three etcd replicas are functioning.
If you set antiAffinityGroups.enabled to true in the admin cluster
configuration file, GKE on VMware automatically creates vSphere DRS
anti-affinity rules for the three nodes that run the user cluster control plane.
This causes those VMs to be spread across three physical hosts.
GKE on VMware also creates vSphere DRS anti-affinity rules for the worker nodes in your user cluster, which causes those nodes to be spread across at least three physical hosts. Multiple DRS anti-affinity rules are used per user cluster node-pool based on the number of nodes. This ensures that the worker nodes can find hosts to run on, even when the number of hosts is less than the number of VMs in the user cluster node-pool. We recommend that you include extra physical hosts in your vCenter cluster. Also configure DRS to be fully automated so that in case a host becomes unavailable, DRS can automatically restart VMs on other available hosts without violating the VMs' anti-affinity rules.
GKE on VMware maintains a special node label,
onprem.gke.io/failure-domain-name, whose value is set to the underlying ESXi
host name. User applications that want high availability can set up
podAntiAffinity rules with this label as the topologyKey to ensure that
their application Pods are spread across different VMs as well as physical hosts.
You can also configure multiple node pools for a user cluster with different
datastores and special node labels. Similarly, you can set up podAntiAffinity
rules with that special node label as the topologyKey to achieve higher
availability upon datastore failures.
To have HA for user workloads, ensure that the user cluster has a sufficient number
of replicas under nodePools.replicas, which ensures the desired number of user
cluster worker nodes in running condition.
You can use separate datastores for admin clusters and user clusters to isolate their failures.
Load balancer
There are two types of load balancers that you can use for high availability.
Bundled MetalLB load balancer
For the
bundled MetalLB load balancer,
you achieve HA by having more than one node with enableLoadBalancer: true.
MetalLB distributes services onto the load balancer nodes but for a single service, there is only one leader node handling all traffic for that service.
During the cluster upgrade, there is some downtime when the load balancer nodes are upgraded. The duration of failover disruption of MetalLB grows as the number of load balancer nodes increases. With less than 5 nodes, the disruption is within 10 seconds.
Bundled Seesaw load balancer
For the
bundled Seesaw load balancer,
you can enable HA by setting
loadBalancer.seesaw.enableHA to true in the cluster configuration file.
You must also enable a combination of MAC learning, forged transmits,
and promiscuous mode on your load balancer port group.
With HA, two load balancers are set up in active-passive mode. If the active load balancer has a problem, the traffic fails over to the passive load balancer.
During an upgrade of a load balancer, there is some downtime. If HA is enabled for the load balancer, the maximum downtime is two seconds.
Integrated F5 BIG-IP load balancer
The F5 BIG-IP platform provides various Services to help you enhance the security, availability, and performance of your applications. For GKE on VMware, BIG-IP provides external access and L3/4 load balancing Services.
For more information, see BIG-IP high availability.
Using multiple clusters for disaster recovery
Deploying applications in multiple clusters across multiple vCenters or GKE Enterprise platforms can provide higher global availability and limit the blast radius during outages.
This setup uses the existing GKE Enterprise cluster in the secondary data center for disaster recovery rather than setting up a new cluster. Following is a high-level summary to achieve this:
Create another admin cluster and user cluster in the secondary data center. In this multi-cluster architecture, we require users to have two admin clusters in each data center, and each admin cluster runs a user cluster.
The secondary user cluster has a minimal number of worker nodes (three) and is a hot standby (always running).
Application deployments can be replicated across the two vCenters by using Config Sync, or the preferred approach is to use an existing application DevOps (CI/CD, Spinnaker) toolchain.
In the event of a disaster, the user cluster can be resized to the number of nodes.
Additionally, a DNS switchover is required to route traffic between the clusters to the secondary data center.