En esta página, se describen las opciones de alta disponibilidad en GKE on VMware.
Funcionalidad principal
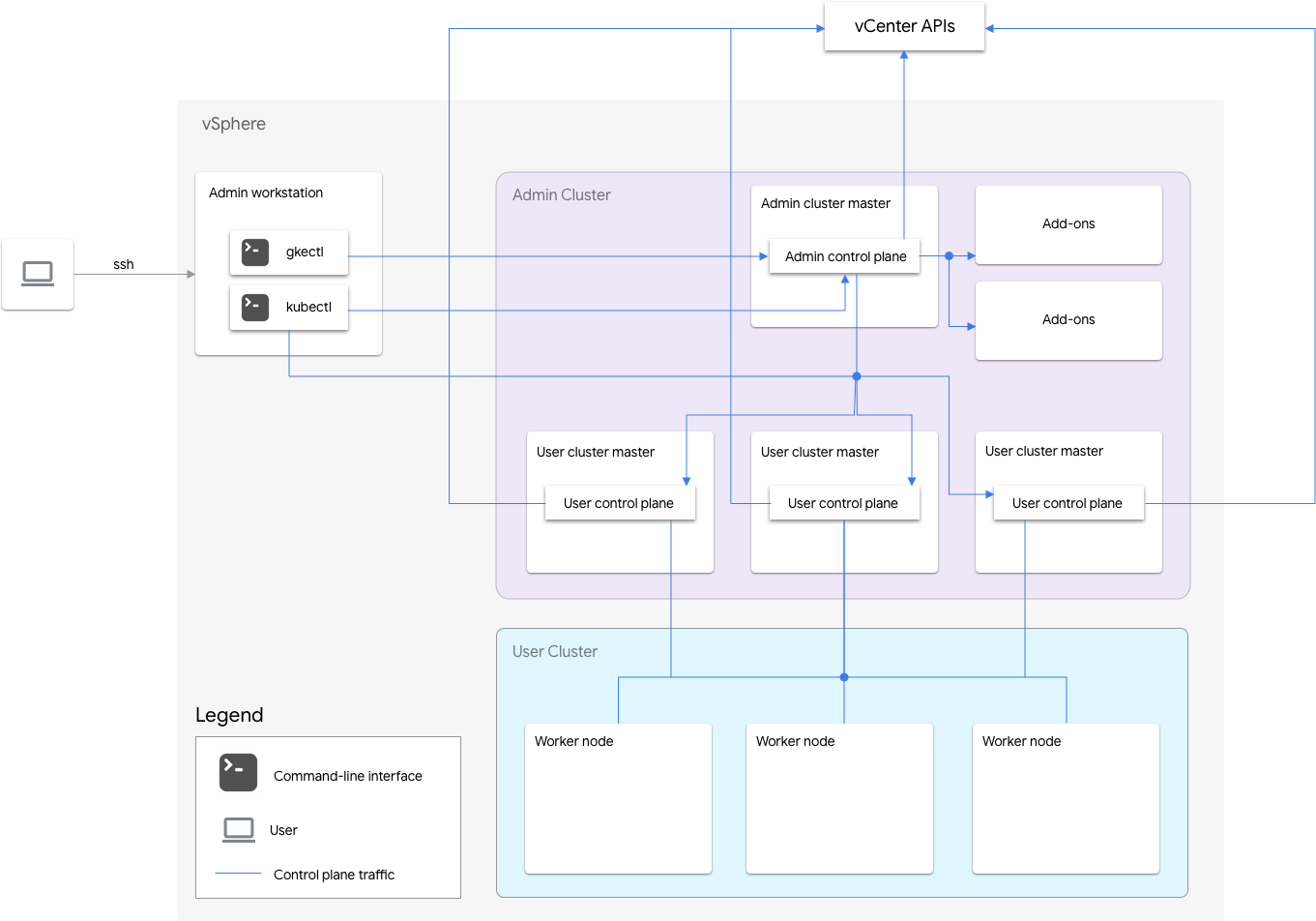
GKE en VMware incluye un clúster de administrador y uno o más clústeres de usuario.
El clúster de administrador administra el ciclo de vida de los clústeres de usuario, incluida la creación, las actualizaciones y la eliminación de clústeres del usuario. En el clúster de administrador, la instancia principal de administrador administra los nodos trabajadores del administrador, que incluyen las instancias principales de usuario (nodos que ejecutan el plano de control de los clústeres de usuario administrados) y los nodos de complemento (nodos que ejecutan los componentes complementarios compatibles con la funcionalidad del clúster de administrador).
Para cada clúster de usuario, el clúster de administrador tiene un nodo que no es de alta disponibilidad o tres nodos de alta disponibilidad que ejecutan el plano de control. El plano de control incluye el servidor de la API de Kubernetes, el programador de Kubernetes, el administrador de controladores de Kubernetes y varios controladores críticos para el clúster de usuario.
La disponibilidad del plano de control del clúster del usuario es fundamental para las operaciones de carga de trabajo, como la creación, el escalamiento vertical, la disminución de escalamiento y la finalización de la carga de trabajo. En otras palabras, una interrupción del plano de control no interfiere en las cargas de trabajo en ejecución, pero las cargas de trabajo existentes pierden las capacidades de administración del servidor de la API de Kubernetes si su plano de control está ausente.
Las cargas de trabajo y los servicios alojados en contenedores se implementan en los nodos trabajadores del clúster de usuario. Cualquier nodo de trabajador único no debe ser fundamental para la disponibilidad de la aplicación, siempre y cuando la aplicación se implemente con Pods redundantes programados en varios nodos trabajadores.
Habilita la alta disponibilidad
vSphere y GKE en VMware proporcionan una serie de funciones que contribuyen a la alta disponibilidad (HA).
vSphere HA y vMotion
Recomendamos habilitar las siguientes dos funciones en el clúster de vCenter que aloja tus clústeres de GKE on VMware:
Estas características mejoran la disponibilidad y la recuperación en caso de que un host de ESXi falle.
La alta disponibilidad de vCenter usa varios hosts ESXi configurados como clústeres a fin de proporcionar una recuperación rápida de las interrupciones y una alta disponibilidad rentable para aplicaciones que se ejecutan en máquinas virtuales. Te recomendamos que aprovisiones el clúster de vCenter con hosts adicionales y habilites vSphere HA Host Monitoring con Host Failure Response configurado como Restart VMs. Las VM se pueden reiniciar de forma automática en otros hosts disponibles en caso de que falle el host de ESXi.
vMotion permite la migración en vivo de VM sin tiempo de inactividad de un host de ESXi a otro. Para el mantenimiento planificado del host, puedes usar la migración en vivo de vMotion a fin de evitar el tiempo de inactividad de la aplicación por completo y garantizar la continuidad del negocio.
Clúster de administrador
GKE en VMware admite la creación de clústeres de administrador con alta disponibilidad (HA). Un clúster de administrador de alta disponibilidad tiene tres nodos que ejecutan los componentes del plano de control. Para obtener información sobre los requisitos y las limitaciones, consulta Clúster de administrador de alta disponibilidad.
Ten en cuenta que la falta de disponibilidad del plano de control del clúster de administrador no afecta la funcionalidad del clúster de usuario existente ni a las cargas de trabajo que se ejecutan en clústeres de usuario.
Existen dos nodos de complementos en un clúster de administrador. Si una está inactiva, la otra aún puede entregar las operaciones del clúster de administrador. Para obtener redundancia, GKE en VMware distribuye servicios de complementos críticos, como kube-dns, entre ambos nodos del complemento.
Si configuras antiAffinityGroups.enabled como true en el archivo de configuración del clúster de administrador, GKE en VMware crea de forma automática reglas de antiafinidad de vSphere DRS para los nodos del complemento, lo que hace que se distribuyan en dos hosts físicos para la alta disponibilidad.
Clúster de usuario
Puedes habilitar la lata disponibilidad en un clúster de usuarios si configuras masterNode.replicas como 3 en el archivo de configuración de clústeres de usuario. Si el clúster de usuario tiene habilitado Plano de control V2 (recomendado), los 3 nodos del plano de control se ejecutan en el clúster de usuario.
Los clústeres de usuario de kubeception heredados con alta disponibilidad ejecutan los tres nodos del plano de control en el clúster de administrador. Cada nodo del plano de control también ejecuta una réplica de etcd. El clúster de usuario continúa funcionando mientras haya un plano de control en ejecución y un quórum de etcd. Un quórum de etcd requiere que dos de las tres réplicas de etcd funcionen.
Si configuras antiAffinityGroups.enabled como true en el archivo de configuración del clúster de administrador, GKE en VMware crea de forma automática reglas de antiafinidad de DRS de vSphere para los tres nodos que ejecutan el plano de control del clúster de usuario.
Esto hace que esas VM se distribuyan en tres hosts físicos.
GKE en VMware también crea reglas de antiafinidad de DRS de vSphere para los nodos trabajadores en el clúster de usuario, lo que hace que esos nodos se distribuyan en al menos tres hosts físicos. Se usan varias reglas de antiafinidad de DRS por grupo de nodos del clúster de usuario según la cantidad de nodos. Esto garantiza que los nodos trabajadores puedan encontrar hosts para ejecutar, incluso cuando la cantidad de hosts sea menor que la cantidad de VM en el grupo de nodos del clúster de usuario. Te recomendamos que incluyas hosts físicos adicionales en tu clúster de vCenter. Además, configura DRS para que esté automatizada por completo, de modo que en caso de que un host no esté disponible, DRS puede reiniciar automáticamente las VM en otros hosts disponibles sin infringir las reglas de antiafinidad de las VM.
GKE en VMware mantiene una etiqueta de nodo especial, onprem.gke.io/failure-domain-name, cuyo valor se establece en el nombre de host de ESXi subyacente. Las aplicaciones de usuario que quieren alta disponibilidad pueden configurar reglas podAntiAffinity con esta etiqueta como topologyKey para garantizar que sus Pods de aplicación se distribuyan en diferentes VM y hosts físicos.
También puedes configurar varios grupos de nodos para un clúster de usuarios con diferentes almacenes de datos y etiquetas especiales de nodo. Del mismo modo, puedes configurar reglas de podAntiAffinity con esa etiqueta de nodo especial como topologyKey para lograr una mayor disponibilidad ante fallas del almacén de datos.
Para tener alta disponibilidad en las cargas de trabajo de usuario, asegúrate de que el clúster de usuarios tenga una cantidad suficiente de réplicas en nodePools.replicas, lo que garantiza la cantidad deseada de nodos trabajadores del clúster de usuario en la condición en ejecución.
Puedes usar almacenes de datos distintos para los clústeres de administración y los clústeres de usuarios a fin de aislar sus fallas.
Balanceador de cargas
Existen dos tipos de balanceadores de cargas que puedes usar para la alta disponibilidad.
Balanceador de cargas en paquete de MetalLB
Para el balanceador de cargas de MetalLB agrupado, obtienes alta disponibilidad cuando tienes más de un nodo con enableLoadBalancer: true.
MetalLB distribuye servicios en los nodos del balanceador de cargas, pero, para un solo servicio, solo hay un nodo líder que controla todo el tráfico de ese servicio.
Durante la actualización del clúster, hay cierto tiempo de inactividad cuando se actualizan los nodos del balanceador de cargas. La duración de la interrupción de la conmutación por error de MetalLB aumenta a medida que lo hace la cantidad de nodos del balanceador de cargas. Con menos de 5 nodos, la interrupción ocurre en un plazo de 10 segundos.
Balanceador de cargas de Seesaw en paquetes
Para el elemento Balanceador de cargas de Seesaw en paquetes, puedes habilitar la alta disponibilidad mediante la configuración de loadBalancer.seesaw.enableHA como true en el archivo de configuración del clúster.
También debes habilitar una combinación de aprendizaje MAC, transmisiones falsificadas y el modo abundante en el grupo de puertos del balanceador de cargas.
Con la alta disponibilidad, se configuran dos balanceadores de cargas en modo activo/pasivo. Si el balanceador de cargas activo tiene un problema, el tráfico falla en el balanceador de cargas pasivo.
Durante una actualización de un balanceador de cargas, existe un tiempo de inactividad. Si la alta disponibilidad está habilitada en el balanceador de cargas, el tiempo de inactividad máximo es de dos segundos.
Balanceador de cargas BIG-IP de F5 integrado
La plataforma BIG-IP de F5 ofrece varios servicios para ayudarte a mejorar la seguridad, la disponibilidad y el rendimiento de tus aplicaciones. Para GKE on VMware, BIG-IP proporciona acceso externo y servicios de balanceo de cargas L3/4.
Para obtener más información, consulta la alta disponibilidad de BIG-IP.
Usa varios clústeres para la recuperación ante desastres
Implementar aplicaciones en varios clústeres en varias plataformas de vCenter o GKE Enterprise puede proporcionar una mayor disponibilidad global y limitar el radio de impacto durante las interrupciones.
En esta configuración, se usa el clúster de GKE Enterprise existente en el centro de datos secundario para la recuperación ante desastres, en lugar de configurar un clúster nuevo. A continuación, se ofrece un resumen de alto nivel para lograrlo:
Crear otro clúster de administrador y clúster de usuarios en el centro de datos secundario En esta arquitectura de varios clústeres, exigimos que los usuarios tengan dos clústeres de administrador en cada centro de datos, y cada clúster de administrador ejecuta un clúster de usuario.
El clúster de usuario secundario tiene una cantidad mínima de nodos trabajadores (tres) y es una espera activa (siempre en ejecución).
Las implementaciones de aplicaciones se pueden replicar en los dos vCenter mediante el Sincronizador de configuración, o el enfoque preferido es usar una cadena de herramientas de DevOps de la aplicación existente (CI/CD, Spinnaker).
En caso de un desastre, se puede cambiar el tamaño del clúster de usuarios a la cantidad de nodos.
Además, se requiere un cambio de DNS para enrutar el tráfico entre los clústeres al centro de datos secundario.