Anthos Service Mesh provides GKE Enterprise users with tools to monitor and manage reliable microservice-based applications. This tutorial uses the Bank of Anthos sample deployment on Google Cloud to introduce you to some of Anthos Service Mesh's service management features by showing you how to define a service level objective (SLO). The sample deploys a real GKE Enterprise hands-on environment with a GKE cluster, service mesh, and a Bank of Anthos application with multiple microservices.
What is an SLO?
According to Google's Site Reliability Engineering (SRE) book:
It's impossible to manage a service correctly, let alone well, without understanding which behaviors really matter for that service and how to measure and evaluate those behaviors. To this end, we would like to define and deliver a given level of service to our users, whether they use an internal API or a public product.
Google SRE teams use service level indicators (SLIs), service level objectives (SLOs), and service level agreements (SLAs) to structure and guide the metrics that inform their work. An SLI is a quantitative measure of some aspect of how your service is performing, such as its latency or availability, while an SLO is a target value ("this should happen x% of the time") for a service level that is measured by an SLI. Anthos Service Mesh makes it easy to define and refine SLOs for your own services. It gives you the information that you need to identify appropriate SLIs and SLOs, and notifies you when your service isn't meeting its SLOs.
To find out more about SLOs and SLIs in Anthos Service Mesh, see the SLO overview and Designing SLOs.
Objectives
In this tutorial, you're introduced to managing services with Anthos Service Mesh in GKE Enterprise through the following tasks:
Identify a service level indicator (SLI) for a service
Use a service level objective (SLO) to monitor for unexpected behavior.
Costs
Deploying the Bank of Anthos application will incur pay-as-you-go charges for GKE Enterprise on Google Cloud as listed on our Pricing page, unless you have already purchased a subscription.
You are also responsible for other Google Cloud costs incurred while running the Bank of Anthos application, such as charges for Compute Engine VMs and load balancers.
We recommend cleaning up after finishing the tutorial or exploring the deployment to avoid incurring further charges.
Before you begin
This tutorial is a follow up to the Explore GKE Enterprise tutorial. Before starting this tutorial, follow the instructions on that page to set up your project and deploy Bank of Anthos.
Identifying SLIs
Anthos Service Mesh makes gathering SLIs and defining your SLOs a simple,
straightforward task. In our example, you decide to first define an SLO for
the Bank of Anthos' ledgerwriter service.
First use Anthos Service Mesh to find information that you could use to identify an SLI for the service.
Go to the Anthos Service Mesh page in the project where you installed Bank of Anthos.
Go to the Anthos Service Mesh page
The top part of this view shows the current status of your application's services along with indicators for alerts and SLOs, including the count of services without SLOs; currently all of the services are under No SLOs set. In addition, in the Status column, all of the services have a black circle indicator. If you hold the pointer over that indicator for any service, you're informed that no SLO is set for the service.
Note the value in ms for 99% latency for
ledgerwriter(you may need to scroll down and across to see it). This metric means that one out of every 100 requests experiences this level of delay. You will use this value in the next section.
Creating an SLO
Now create an SLO against a latency SLI for the service. To see what happens when a service exceeds its error budget, set a threshold that's deliberately low, based on the information that you saw in the previous section. For a real production service you'd try to find a threshold latency value no lower than is necessary for your users to have a good experience from your application.
In the Anthos Service Mesh Table view, click ledgerwriter to go to the service overview page.
Under Service status, click Create an SLO.
In the SLI Type list, select Latency.
Leave the default Request-based evaluation method, and click Continue.
Set Latency Threshold to an arbitrarily low value, such as
10 ms(something significantly lower than the 99% latency value you observed earlier), and click Continue again.In Compliance Period, set Period Type to
Rolling, and Period Length to1 Day.In SLO Goal, set the Compliance target to
90%. Anthos Service Mesh uses this value to calculate the error budget that you have for this SLO; that is, the maximum percentage of requests that should exceed your specified latency threshold. A Preview shows you how your SLO would have performed in the most recent one day period. Click Continue.The Name your SLO section suggests a default name for your new SLO: you can accept the recommended default or specify a new name. To create the SLO and go to the Health page for the
ledgerwriter, click Create SLO.
Click the drop-down arrow to see more details about your SLO. You should see that the SLO is Out of Error Budget based on your settings. You can also edit or delete the SLO from this view.
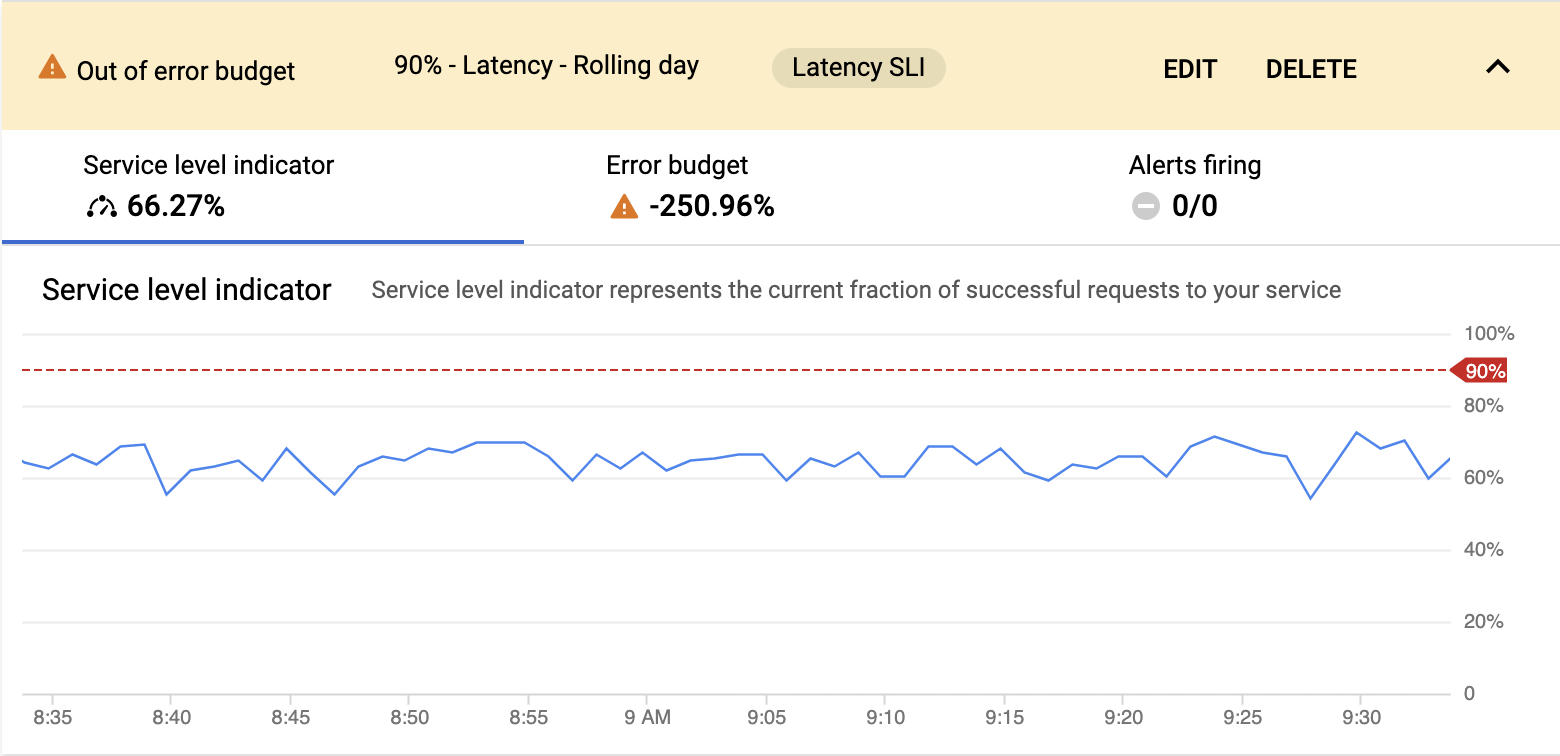
Rechecking SLO and alert indicators
On the service overview page, click the back arrow to return to the table view. Now you can see that the service count for No SLOs set has been reduced by one and that SLOs out of error budget is no longer 0.
If you scroll down to ledgerwriter, notice that the adjacent indicator has changed to an orange warning triangle. If you hold the pointer over that indicator, you're told to investigate service reliability. Clicking the indicator brings you back to the service's Health page to review your SLO details. The same indicator also appears for your service in the topology view.

Exploring the deployment further
There's still lots more to see and do in GKE Enterprise with our deployment. Feel free to try another tutorial or continue to explore the Bank of Anthos deployment on Google Cloud yourself, before following the cleanup instructions in the next section.
Clean up
After you've finished exploring the Bank of Anthos application, you can clean up the resources that you created on Google Cloud so they don't take up quota and you aren't billed for them in the future.
Option 1. You can delete the project. However, if you want to keep the project around, you can use Option 2 to delete the deployment.
Option 2. If you want to keep your current project, you can use
terraform destroyto delete the sample application and cluster.
Delete the project (option 1)
The easiest way to avoid billing is to delete the project you created for this tutorial.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Delete the deployment (option 2)
This approach deletes the Bank of Anthos application and the cluster, but does not delete the project. Run the following commands on your Cloud Shell:
Change to the directory that hosts the installation scripts:
cd bank-of-anthos/iac/tf-anthos-gkeDelete the sample and the cluster:
terraform destroyEnter the project ID when prompted.
If you plan to redeploy, verify that all requirements are met as described in the Before you begin section.
What's next
There's lots more to explore in our GKE Enterprise documentation.
Try more tutorials
Explore GKE Enterprise security features with Bank of Anthos in Secure GKE Enterprise.
Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.
Learn more about GKE Enterprise
Learn more about GKE Enterprise in our technical overview.
Find out how to set up GKE Enterprise in a real production environment in our setup guide.
Find out how to do more with Anthos Service Mesh in the Anthos Service Mesh documentation.