Anthos clusters on VMware(GKE on-prem)は、統合、手動、バンドルの 3 つの負荷分散モードのいずれかで実行できます。このトピックでは、バンドル型負荷分散モードで実行するように Anthos clusters on VMware を構成する方法について説明します。
ここでは手順全体を詳しく解説します。Seesaw ロードバランサの使用方法の概要については、Seesaw ロードバランサ(クイックスタート)をご覧ください。
バンドル型負荷分散モードでは、Anthos clusters on VMware がロードバランサを提供し、管理します。ロードバランサにライセンスを割り当てる必要はありません。必要なセットアップ作業は最小限に抑えられます。
Anthos clusters on VMware が提供するバンドル型ロードバランサは、Seesaw ロードバランサです。
バンドル型負荷分散モードの利点
バンドル型負荷分散モードには、手動負荷分散モードに比べて次のような利点があります。
単一のチームがクラスタの作成とロードバランサの構成の両方を担当できます。たとえば、クラスタ管理チームは、事前にロードバランサの取得、実行、構成を別のネットワーキング チームに頼む必要はありません。
Anthos clusters on VMware は、ロードバランサ上で仮想 IP アドレス(VIP)を自動的に構成します。クラスタの作成時に、Anthos clusters on VMware は Kubernetes API サーバー、Ingress サービス、クラスタ アドオンの VIP を使用してロードバランサを構成します。クライアントが LoadBalancer タイプの Service を作成すると、Anthos clusters on VMware はロードバランサ上に Service の VIP を自動的に構成します。
組織、グループ、管理者の間の依存関係が軽減されます。特に、クラスタを管理するグループは、ネットワークを管理するグループにあまり依存しないようになります。
おすすめのバージョン
バンドル型負荷分散モードには、vSphere 6.7 以降と仮想分散スイッチ(VDS)6.6 以降を使用することを強くおすすめします。
必要に応じて、以前のバージョンを使用することもできますが、インストールの安全性は低下します。このトピックの残りのセクションでは、vSphere 6.7 以降と VDS 6.6 以降を使用する際のセキュリティ上の利点について詳しく説明します。
VLAN の計画
Anthos clusters on VMware のインストールには、1 つの管理クラスタと 1 つ以上のユーザー クラスタがあります。バンドル型負荷分散モードでは、クラスタを別々の VLAN に配置することを強くおすすめします。特に管理クラスタは独自の VLAN に配置することが推奨されます。
管理クラスタが専用の VLAN 上に存在する場合、コントロール プレーンのトラフィックはデータプレーンのトラフィックから分離されます。これにより、管理クラスタとユーザー クラスタのコントロール プレーンが構成ミスから保護されます。このようなミスは、たとえば、同じ VLAN 内のレイヤ 2 ループによるブロードキャスト ストームや、データプレーンとコントロール プレーンの間の望ましい分離を排除する IP アドレスの競合などの問題につながる可能性があります。
バンドル型負荷分散用 VM リソースのプロビジョニング(Seesaw)
バンドル型負荷分散では、発生が予想されるネットワーク トラフィックに従って VM の CPU とメモリのリソースをプロビジョニングします。
バンドル型ロードバランサはメモリ消費量が少なく、メモリ 1 GB の VM で実行できます。ただし、ネットワークのパケットレートが増加すると、より多くの CPU リソースが必要になります。
以下の表に、VM をプロビジョニングする際のストレージ、CPU とメモリのガイドラインを示します。パケットレートはネットワーク パフォーマンスの一般的な測定値ではありません。ネットワーク テーブルには、アクティブなネットワーク接続の最大数に関するガイドラインも表示されます。このガイドラインは、VM に 10 Gbps のリンクがあり、CPU が 70% 未満の容量で実行される環境を前提としています。
バンドル型ロードバランサが高可用性(HA)モードで実行されると、アクティブとバックアップのペアが実行され、すべてのトラフィックが 1 つの VM を通過します。
実際の使用例は変化するため、これらのガイドラインは実際のトラフィックに基づいて変更する必要があります。CPU とパケットレートの指標をモニタリングして、必要な変更を行います。
Seesaw VM の CPU とメモリを変更する場合は、ロードバランサのアップグレード手順をご覧ください。バンドルされたロードバランサの同じバージョンを維持し、CPU の数とメモリ割り当てのみを変更できます。
小規模な管理クラスタの場合は 2 つの CPU を、大規模な管理クラスタの場合は 4 つの CPU をおすすめします。
| ストレージ | CPU | メモリ | パケットレート(pps) | アクティブ接続の最大数 |
|---|---|---|---|---|
| 20 GB | 1(非本番環境) | 1 GB | 250,000 | 100 |
| 20 GB | 2 | 3 GB | 450,000 | 300 |
| 20 GB | 4 | 3 GB | 850,000 | 6,000 |
| 20 GB | 6 | 3 GB | 1,000,000 | 10,000 |
本番環境以外では単一の CPU のみをプロビジョニングする必要があります。
仮想 IP アドレスの確保
負荷分散モードのどれを選択するかにかかわらず、負荷分散に使用する仮想 IP アドレス(VIP)をいくつか確保する必要があります。この VIP により、外部クライアントは Kubernetes API サーバー、Ingress Service、アドオン サービスにアクセスできます。
管理クラスタの VIP のセットと、作成する各ユーザー クラスタの VIP のセットを確保する必要があります。任意のクラスタの VIP は、クラスタノードとそのクラスタの Seesaw VM と同じ VLAN 上にある必要があります。
VIP の設定方法については、管理クラスタの作成をご覧ください。
ノード IP アドレスの確保
バンドル型負荷分散モードでは、クラスタノードの静的 IP アドレスを指定することも、クラスタノードが DHCP サーバーから IP アドレスを取得することもできます。
クラスタノードに静的 IP アドレスを割り当てる場合は、管理クラスタ内のノードと、作成するすべてのユーザー クラスタのノードに十分な数のアドレスを確保します。設定するノード IP アドレスの数の詳細については、管理クラスタの作成をご覧ください。
Seesaw VM の IP アドレスの確保
次に、Seesaw ロードバランサを実行する VM の IP アドレスを確保します。
確保するアドレスの数は、高可用性(HA)の Seesaw ロードバランサか非 HA Seesaw ロードバランサを作成するかによって異なります。
ケース 1: HA Seesaw ロードバランサ
管理クラスタでは、Seesaw VM のペア用に 2 つの IP アドレスを確保します。また、管理クラスタでは、Seesaw VM のペア用に単一のマスター IP アドレスを確保します。これら 3 つのアドレスはすべて、管理クラスタノードと同じ VLAN 上にある必要があります。
作成するユーザー クラスタごとに、Seesaw VM のペアごとに 2 個の IP アドレスを確保します。また、ユーザー クラスタごとに、Seesaw VM のペアに単一のマスター IP アドレスを確保します。任意のユーザー クラスタで、これら 3 つのアドレスはすべて、ユーザー クラスタノードと同じ VLAN 上にある必要があります。
ケース 2: 非 HA Seesaw ロードバランサ
管理クラスタでは、Seesaw VM 用に 1 個の IP アドレスを確保します。管理クラスタ用に、Seesaw ロードバランサのマスター IP アドレスも確保します。これらのアドレスは両方とも、管理クラスタノードと同じ VLAN 上にある必要があります。
作成するユーザー クラスタごとに、Seesaw VM 用に 1 個の IP アドレスを確保します。また、各ユーザー クラスタ用に、Seesaw ロードバランサのマスター IP アドレスも確保します。これらのアドレスは両方とも、ユーザー クラスタノードと同じ VLAN 上にある必要があります。
ポートグループの計画
Seesaw VM ごとに 2 つのネットワーク インターフェースがあります。これらのネットワーク インターフェースの 1 つは VIP で構成されています。他のネットワーク インターフェースは、指定した IP ブロック ファイルから取得した IP アドレスで構成されています。
個々の Seesaw VM では、2 つのネットワーク インターフェースを同じ vSphere ポートグループに接続することも、別々のポートグループに接続することもできます。ポートグループが別々の場合は、同じ VLAN 上にある必要があります。
このトピックでは、次の 2 つのポートグループを参照します。
ロードバランサ ポートグループ: Seesaw VM の場合、VIP で構成されたネットワーク インターフェースがこのポートグループに接続されます。
クラスタノード ポート グループ: Seesaw VM の場合、IP ブロック ファイルから取得された IP アドレスで構成されるネットワーク インターフェースがこのポートグループに接続されます。クラスタノードも、このポートグループに接続されます。
ロードバランサ ポートグループとクラスタノード ポートグループは同じものにできます。ただし、これらは別々にすることを強くおすすめします。
次の図では、Seesaw 負荷分散の推奨ネットワーク構成を示します。
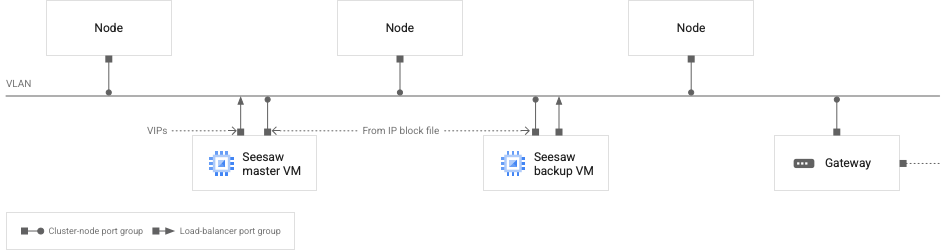 VLAN 上の VM とクラスタノード
VLAN 上の VM とクラスタノード
上の図は、1 つのクラスタ(管理クラスタまたはユーザー クラスタ)を示しています。各クラスタは独自の VLAN に配置することをおすすめします。
この図では、次のネットワークの特性を確認できます。
2 つの Seesaw VM、1 つのマスターと 1 つバックアップがあります。
Seesaw VM はクラスタノードと同じ VLAN 上にあります。
バックアップ Seesaw VM には、ネットワーク インターフェースが 2 つあります。一方のインターフェースは、Seesaw IP ブロック ファイルから取得した IP アドレスで構成されます。もう一方のインターフェースには、IP アドレスは構成されません。
マスター Seesaw VM には、ネットワーク インターフェースが 2 つあります。一方のインターフェースは、Seesaw IP ブロック ファイルから取得した IP アドレスで構成されます。他のインターフェースは VIP で構成されます。
各 Seesaw VM では、1 つのネットワーク インターフェースがロードバランサのポートグループに接続されています。図の他のすべてのネットワーク インターフェースが、クラスタノード ポートのグループに接続されています。
図に示されているネットワーク インターフェースで構成されているすべての IP アドレス(VIP を含む)は、VLAN にルーティング可能である必要があります。
管理クラスタの場合、Seesaw マスター VM 上の VIP インターフェースは、次の IP アドレスで構成されます。
- 管理クラスタのマスター Seesaw VM の VIP
- 管理クラスタのアドオン VIP
- 管理クラスタのコントロール プレーン VIP
- 関連するすべてのユーザー クラスタのコントロール プレーン VIP
- 管理クラスタで実行されている LoadBalancer タイプの Service の VIP
ユーザー クラスタの場合、Seesaw マスター VM 上の VIP インターフェースは、次の IP アドレスで構成されます。
- ユーザー クラスタのマスター Seesaw VM の VIP
- ユーザー クラスタの上り(内向き)VIP
- ユーザー クラスタで実行されている LoadBalancer タイプの Service の VIP
IP ブロック ファイルの作成
作成するクラスタごとに、Seesaw VM に選択したアドレスを IP ブロック ファイルに指定します。この IP ブロック ファイルは、クラスタノードではなく、ロードバランサ VM 用です。クラスタノードに静的 IP アドレスを使用する場合は、それらのアドレスに個別の IP ブロック ファイルを作成する必要があります。次に、Seesaw VM の 2 つの IP アドレスを指定する IP ブロック ファイルの例を示します。
blocks:
- netmask: "255.255.255.0"
gateway: "172.16.20.1"
ips:
- ip: "172.16.20.18"
hostname: "seesaw-vm-1"
- ip: "172.16.20.19"
hostname: "seesaw-vm-2"
構成ファイルの入力
クラスタごとに構成ファイル(1 つの管理クラスタと 1 つ以上のユーザー クラスタ)を準備します。
各クラスタの構成ファイルで、loadBalancer.kind を "Seesaw" に設定します。
loadBalancer で、seesaw セクションに以下を入力します。
loadBalancer:
kind: Seesaw
seesaw:
ipBlockFilePath::
vrid:
masterIP:
cpus:
memoryMB:
vCenter:
networkName:
enableha:
antiAffinityGroups:
enabled:
seesaw.ipBlockFilePath
文字列。Seesaw VM の IP ブロック ファイルのパスに設定します。例:
loadBalancer:
seesaw:
ipBlockFilePath: "admin-seesaw-ipblock.yaml"
seesaw.vrid
整数。Seesaw VM の仮想ルーター識別子。この識別子は VLAN 内で一意なものにする必要があります。有効な範囲は 1~255 です。例:
loadBalancer:
seesaw:
vrid: 125
seesaw.masterIP
文字列。Seesaw ロードバランサのマスター IP アドレス。例:
loadBalancer:
seesaw:
masterIP: 172.16.20.21
seesaw.cpus
整数。各 Seesaw VM の CPU 数。次に例を示します。
loadBalancer:
seesaw:
cpus: 4
seesaw.memoryMB
整数。各 Seesaw VM のメモリ容量(MB)。次に例を示します。
loadBalancer:
seesaw:
memoryMB: 3072
seesaw.vCenter.networkName
文字列。Seesaw VM を含むネットワークの名前。設定されていない場合は、クラスタと同じネットワークを使用します。例:
loadBalancer:
seesaw:
vCenter:
networkName: "my-seesaw-network"
seesaw.enableHA
ブール値。高可用性の Seesaw ロードバランサを作成する場合は、これを true に設定します。それ以外の場合は false に設定します。例:
loadBalancer:
seesaw:
enableHA: true
enableha を true に設定する場合は、MAC ラーニングを有効にする必要があります。
seesaw.antiAffinityGroups.enabled
アンチアフィニティ ルールを Seesaw VM に適用する場合は、seesaw.antiAffinityGroups.enabled の値を true に設定します。それ以外の場合は、値を false に設定します。デフォルト値は true です。推奨値は true です。これにより、可能な場合はいつでも Seesaw VM が異なる物理ホストに配置されます。例:
loadBalancer:
seesaw
antiAffinityGroups:
enabled: true
MAC ラーニングまたは無作為モードの有効化(HA のみ)
非 HA Seesaw ロードバランサを設定する場合は、このセクションをスキップできます。
loadBalancer.seesaw.disableVRRPMAC を正に設定した場合、MAC 学習構成は不要です。ただし、ネットワークが Gratuitous ARP を使用して IP フェイルオーバーをサポートしている必要があります。ユーザー クラスタの構成ファイルをご覧ください。
HA Seesaw ロードバランサをセットアップしていて、loadBalancer.seesaw.disableVRRPMAC を false に設定している場合は、ロードバランサのポートグループで、MAC ラーニング、偽装送信、プロミキャスト モードの組み合わせを有効化する必要があります。
こうした機能を有効にする方法は、スイッチのタイプによって異なります。
| スイッチのタイプ | 機能の有効化 | セキュリティへの影響 |
|---|---|---|
| vSphere 7.0 VDS |
vSphere 7.0 HA では、loadBalancer.seesaw.disableVRRPMAC を true に設定する必要があります。MAC ラーニングはサポートされていません。 |
|
| vSphere 6.7 と VDS 6.6 |
次のコマンドを実行し、ロードバランサの MAC ラーニングと偽造送信を有効にします。 |
最小。ロードバランサ ポートグループが Seesaw VM にのみ接続されている場合、MAC ラーニングを信頼できる Seesaw VM のみに制限できます。 |
vSphere 6.5 または VDS のバージョンが 6.6 より前のバージョンの vSphere 6.7 |
ロードバランサ ポートグループの無作為モードと偽造転送を有効にします。[ネットワーキング] タブのポートグループ ページで vSphere のユーザー インターフェースを使用します([設定を編集] -> [セキュリティ])。 | ロードバランサ ポートグループのすべての VM は無作為モードです。そのため、ロードバランサ ポートグループのどの VM もすべてのトラフィックを表示できます。ロードバランサ ポートグループが Seesaw VM にのみ接続されている場合、すべてのトラフィックを表示できるのはそれらの VM のみです。 |
| NSX-T 論理スイッチ | 論理スイッチで MAC ラーニングを有効化します。 | vSphere は、同じレイヤ 2 ドメインに 2 つの論理スイッチを作成することをサポートしていません。そのため、Seesaw VM とクラスタノードは同じ論理スイッチ上にある必要があります。これは、すべてのクラスタノードで MAC ラーニングが有効であることを意味します。攻撃者がクラスタ内で特権 Pod を運用中にすることで、MAC なりすましを実現できる可能性があります。 |
| vSphere Standard Switch | ロードバランサ ポートグループの無作為モードと偽造転送を有効にします。各 ESXI ホストで vSphere のユーザー インターフェースを使用します([構成] -> [仮想スイッチ] -> [Standard Switch] -> [ポートグループの設定を編集] -> [セキュリティ])。 | ロードバランサ ポートグループのすべての VM は無作為モードです。そのため、ロードバランサ ポートグループのどの VM もすべてのトラフィックを表示できます。ロードバランサ ポートグループが Seesaw VM にのみ接続されている場合、すべてのトラフィックを表示できるのはそれらの VM のみです。 |
構成ファイルのプリフライト チェックの実行
IP ブロック ファイルと管理クラスタの構成ファイルを作成したら、構成ファイルにプリフライト チェックを実行します。
gkectl check-config --config [ADMIN_CONFIG_FILE]
ここで、[ADMIN_CONFIG_FILE] は管理クラスタの構成ファイルのパスです。
ユーザー クラスタ構成ファイルの場合は、コマンドに管理クラスタの kubeconfig ファイルを含める必要があります。
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] check-config --config [USER_CONFIG_FILE]
ここで、[ADMIN_CLUSTER_KUBECONFIG] は管理クラスタの kubeconfig ファイルのパスです。
プリフライト チェックに失敗した場合は、必要に応じてクラスタ構成ファイルと IP ブロック ファイルを調整します。その後、プリフライト チェックを再度実行します。
OS イメージのアップロード
次のコマンドを実行して、vSphere 環境に OS イメージをアップロードします。
gkectl prepare --config [ADMIN_CONFIG_FILE]
ここで、[ADMIN_CONFIG_FILE] は管理クラスタの構成ファイルのパスです。
バンドル型負荷分散モードを使用する管理クラスタの作成
管理クラスタのロードバランサ用の VM を作成して構成します。
gkectl create loadbalancer --config [CONFIG_FILE]
ここで、[CONFIG_FILE] は管理クラスタの構成ファイルのパスです。
管理クラスタを作成します。
gkectl create admin --config [CONFIG_FILE]
ここで、[CONFIG_FILE] は管理クラスタの構成ファイルのパスです。
バンドル型負荷分散モードを使用するユーザー クラスタの作成
ユーザー クラスタのロードバランサ用の VM を作成して構成します。
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] create loadbalancer --config [CONFIG_FILE]
ユーザー クラスタを作成します。
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] create cluster --config [CONFIG_FILE]
ここで、[ADMIN_CLUSTER_KUBECONFIG] は管理クラスタの kubeconfig ファイルのパス、[CONFIG_FILE] はユーザー クラスタ構成ファイルのパスです。
パフォーマンスと負荷テスト
アプリケーションのダウンロード スループットは、バックエンドの数に比例します。これは、ロードバランサを迂回し、Direct Server Return を使用して、バックエンドがクライアントに直接レスポンスを送信するためです。
対照的に、アプリケーションのアップロード スループットは、負荷分散を実行する 1 つの Seesaw VM の処理能力によって制限されます。
必要な CPU とメモリの量はアプリケーションによって異なるため、多数のクライアントへの運用を開始する前に負荷テストを行うことが非常に重要です。
テストでは、6 個の CPU と 3 GB のメモリを備えた 1 つの Seesaw VM が、10 K の同時 TCP 接続で 10 GB/秒(ラインレート)のアップロードのトラフィックを処理できることが示されています。ただし、多数の同時 TCP 接続のサポートを計画している場合は、独自の負荷テストを実行することが重要です。
スケーリングの上限
バンドル型負荷分散では、クラスタのスケーリングに上限があります。クラスタ内のノード数には上限があり、ロードバランサで構成できるサービス数にも上限があります。ヘルスチェックにも上限があります。ヘルスチェック数は、ノード数と Service 数の両方に依存します。
バージョン 1.3.1 以降では、ヘルスチェックの数はノードの数とトラフィックのローカル Service の数によって異なります。トラフィックのローカル サービスは、externalTrafficPolicy が "Local" に設定された Service です。
| バージョン 1.3.0 | バージョン 1.3.1 以降 | |
|---|---|---|
| 最大サービス数(S) | 100 | 500 |
| 最大ノード数(N) | 100 | 100 |
| 最大ヘルスチェック数 | S * N <= 10K | N + L * N <= 10K、L はトラフィックのローカル サービス数 |
例: バージョン 1.3.1 では、100 個のノードと 99 個のトラフィックのローカル サービスがあります。この場合、ヘルスチェックの数は 100 + 99 × 100 = 10,000 となります。これは上限 10,000 の範囲内です。
管理クラスタのロードバランサのアップグレード
v1.4 以降では、クラスタのアップグレード時にロードバランサがアップグレードされます。ロードバランサを個別にアップグレードするために、他のコマンドを実行する必要はありません。ただし、以下の gkectl upgrade loadbalancer を使用して、一部のパラメータを更新することはできます。
Seesaw VM の CPU とメモリを更新できます。次の例では、新しい構成ファイルを作成し、Seesaw VM の CPU とメモリを設定します。空白のままにすると、変更されません。bundlePath が設定されている場合、バンドルで指定されたパスにロードバランサがアップグレードされます。
次に例を示します。
apiVersion: v1
kind: AdminCluster
bundlePath:
loadBalancer:
kind: Seesaw
seesaw:
cpus: 3
memoryMB: 3072
次に、以下のコマンドを実行してロードバランサをアップグレードします。
gkectl upgrade loadbalancer --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --config [ADMIN_CLUSTER_CONFIG] --admin-cluster
ここで
[ADMIN_CLUSTER_KUBECONFIG] は、管理クラスタの kubeconfig ファイルです。
[ADMIN_CLUSTER_CONFIG] は、作成した管理クラスタの構成ファイルです。
ロードバランサのアップグレード中は、ダウンタイムが発生することがあります。ロードバランサで HA が有効になっている場合、ダウンタイムは最大 2 秒です。
ユーザー クラスタのロードバランサのアップグレード
v1.4 以降では、クラスタのアップグレード時にロードバランサがアップグレードされます。ロードバランサを個別にアップグレードするために、他のコマンドを実行する必要はありません。ただし、以下の gkectl upgrade loadbalancer を使用して、一部のパラメータを更新することはできます。
Seesaw VM の CPU とメモリを更新できます。次の例では、新しい構成ファイルを作成し、Seesaw VM の CPU とメモリを設定します。空白のままにすると、変更されません。gkeOnPremVersion が設定されている場合、このバージョンで指定されたロードバランサがアップグレードされます。
例:
apiVersion: v1
kind: UserCluster
name: cluster-1
gkeOnPremVersion:
loadBalancer:
kind: Seesaw
seesaw:
cpus: 4
memoryMB: 3072
次に、以下のコマンドを実行してロードバランサをアップグレードします。
gkectl upgrade loadbalancer --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --config [USER_CLUSTER_CONFIG]
ここで
[ADMIN_CLUSTER_KUBECONFIG] は、管理クラスタの kubeconfig ファイルです。
[USER_CLUSTER_CONFIG] は、作成したユーザー構成ファイルです。
[CLUSTER_NAME] は、アップグレードするクラスタの名前です。
Seesaw のログの表示
Seesaw がバンドルされたロードバランサでは、Seesaw VM のログファイルが /var/log/seesaw/ に保存されます。最も重要なログファイルは seesaw_engine.INFO です。
v1.6 以降で Stackdriver が有効になっている場合、ログも Cloud にアップロードされます。このようなリソースは anthos_l4lb リソースで確認できます。ログのアップロードを無効にするには、SSH で VM に接続し、次のコマンドを実行します。
sudo systemctl disable --now docker.fluent-bit.service
Seesaw VM に関する情報の表示
クラスタの Seesaw VM に関する情報は、SeesawGroup のカスタム リソースから取得できます。
クラスタの SeesawGroup のカスタム リソースを表示します。
kubectl --kubeconfig [CLUSTER_KUBECONFIG] get seesawgroups -n kube-system -o yaml
ここで、[CLUSTER_KUBECONFIG] はクラスタの kubeconfig ファイルのパスです。
出力には、VM がトラフィックを処理できる状態かどうかを示す isReady フィールドがあります。出力には、Seesaw VM の名前と IP アドレス、およびどの VM がプライマリであるかも表示されます。
apiVersion: seesaw.gke.io/v1alpha1
kind: SeesawGroup
metadata:
...
name: seesaw-for-cluster-1
namespace: kube-system
...
spec: {}
status:
machines:
- hostname: cluster-1-seesaw-1
ip: 172.16.20.18
isReady: true
lastCheckTime: "2020-02-25T00:47:37Z"
role: Master
- hostname: cluster-1-seesaw-2
ip: 172.16.20.19
isReady: true
lastCheckTime: "2020-02-25T00:47:37Z"
role: Backup
Seesaw 指標の表示
Seesaw がバンドルされたロードバランサには次の指標があります。
- サービスまたはノードあたりのスループット
- サービスまたはノードあたりのパケットレート
- サービスまたはノードあたりのアクティブな接続の数
- CPU とメモリの使用状況
- サービスあたりの正常なバックエンド Pod の数
- プライマリ VM とバックアップ VM
- 稼働率
v1.6 以降では、これらの指標が Stackdriver で Cloud にアップロードされます。これらのリソースは、anthos_l4lb のモニタリング リソースで確認できます。
Prometheus 形式がサポートされている限り、任意のモニタリング ソリューションとダッシュボード ソリューションを使用できます。
ロードバランサの削除
バンドルされた負荷分散を使用するクラスタを削除する場合は、そのクラスタの Seesaw VM を削除する必要があります。これを行うには、vSphere ユーザー インターフェースで Seesaw VM を削除します。
または、1.4.2 以降では、gkectl を実行して構成ファイルを渡すことで、バンドルされているロードバランサとグループ ファイルを削除できます。
管理クラスタの場合は、次のコマンドを実行します。
gkectl delete loadbalancer --config [ADMIN_CONFIG_FILE] --seesaw-group-file [GROUP_FILE]
ユーザー クラスタの場合は、次のコマンドを実行します。
gkectl delete loadbalancer --config [CLUSTER_CONFIG_FILE] --seesaw-group-file [GROUP_FILE] --kubeconfig [ADMIN_CLUSTER_KUBECONFIG]
ここで
[ADMIN_CONFIG_FILE] は、管理クラスタの構成ファイルです。
[CLUSTER_CONFIG_FILE] は、ユーザー クラスタの構成ファイルです。
[ADMIN_CLUSTER_KUBECONFIG] は、管理クラスタの
kubeconfigファイルです。[GROUP_FILE] は、Seesaw グループ ファイルです。グループ ファイルの名前の形式は
seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yamlです。
1.4.2 より前のバージョン
1.4.2 より前のバージョンでは、Seesaw VM と Seesaw グループ ファイルを削除できます。
gkectl delete loadbalancer --config vsphere.yaml --seesaw-group-file [GROUP_FILE]
ここで
[GROUP_FILE] は、Seesaw グループ ファイルです。グループ ファイルは管理ワークステーションの
config.yamlの横にあります。グループ ファイルの名前の形式はseesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yamlです。vsphere.yamlは、vCenter サーバーに関する次の情報が含まれているファイルです。
vcenter:
credentials:
address:
username:
password:
datacenter:
cacertpath:
トラブルシューティング
Seesaw VM への SSH 接続の確立
場合によっては、Seesaw VM に SSH 接続してトラブルシューティングやデバッグを行うこともあります。
SSH 認証鍵の取得
クラスタをすでに作成している場合は、次の手順で SSH 認証鍵を取得します。
クラスタから
seesaw-sshSecret を取得します。Secret から SSH 認証鍵を取得し、base64 でデコードします。デコードした鍵を一時ファイルに保存します。kubectl --kubeconfig [CLUSTER_KUBECONFIG] get -n kube-system secret seesaw-ssh -o \ jsonpath='{@.data.seesaw_ssh}' | base64 -d | base64 -d > /tmp/seesaw-ssh-keyここで、[CLUSTER_KUBECONFIG] はクラスタの kubeconfig ファイルです。
鍵のファイルに適切な権限を設定します。
chmod 0600 /tmp/seesaw-ssh-key
クラスタをまだ作成していない場合は、次の手順で SSH 認証鍵を取得します。
seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yamlという名前のファイルを見つけます。このファイルはグループ ファイルと呼ばれ、
config.yamlの横にあります。また、
gkectl create loadbalancerでグループ ファイルの場所が表示されます。ファイルで
credentials.ssh.privateKeyの値を取得し、base64 でデコードします。デコードした鍵を一時ファイルに保存します。cat seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml | grep privatekey | sed 's/ privatekey: //g' \ | base64 -d > /tmp/seesaw-ssh-key
鍵のファイルに適切な権限を設定します。
chmod 0600 /tmp/seesaw-ssh-key
これで、Seesaw VM に SSH 接続できるようになりました。
ssh -i /tmp/seesaw-ssh-key ubuntu@[SEESAW_IP]
[SEESAW_IP] は、Seesaw VM の IP アドレスです。
スナップショットの取得
--scenario フラグと一緒に gkectl diagnose snapshot コマンドを使用すると、Seesaw VM のスナップショットがキャプチャできます。
--scenario を all や all-with-logs に設定した場合、出力には Seesaw スナップショットと他のスナップショットが含まれます。
--scenario を seesaw に設定した場合、出力には Seesaw スナップショットのみが含まれます。
例:
gkectl diagnose snapshot --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --scenario seesaw
ここで、[ADMIN_CLUSTER_KUBECONFIG] は管理クラスタの kubeconfig ファイルです。
gkectl diagnose snapshot --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --cluster-name [CLUSTER_NAME] --scenario seesaw
gkectl diagnose snapshot --seesaw-group-file [GROUP_FILE] --scenario seesaw
ここで、[GROUP_FILE] はクラスタ用のグループ ファイルのパスです(例: seesaw-for-gke-admin-xxxxxx.yaml)。
既知の問題
Cisco ACI は Direct Server Return(DSR)と連動しない
Seesaw は DSR モードで動作します。デフォルトでは、データプレーン IP 学習が原因で Cisco ACI では機能しません。アプリケーション エンドポイント グループを使用した可能な回避策については、こちらをご覧ください。