Anthos-Cluster auf VMware (GKE On-Prem) können in einem von drei Load-Balancing-Modi ausgeführt werden: integriert, manuell oder gebündelt. In diesem Thema wird beschrieben, wie Anthos-Cluster auf VMware so konfiguriert werden, dass sie im gebündelten Load-Balancing-Modus ausgeführt werden.
Diese Anleitung ist vollständig. Eine kürzere Einführung in die Seesaw-Load-Balancer finden Sie unter Seesaw-Load-Balancer (Kurzanleitung).
Im gebündelten Load-Balancing-Modus stellt Anthos-Cluster auf VMware den Load-Balancer bereit und verwaltet ihn. Sie benötigen keine Lizenz für einen Load-Balancer und die Einrichtung ist einfach.
Der gebündelte Load-Balancer, den Anthos-Cluster auf VMware bereitstellen, ist der Seesaw-Load-Balancer.
Vorteile des gebündelten Load-Balancing-Modus
Der gebündelte Load-Balancing-Modus bietet gegenüber dem manuellen Load-Balancing-Modus folgende Vorteile:
Ein einzelnes Team kann sowohl die Clustererstellung als auch die Konfiguration des Load-Balancing-Modus übernehmen. Ein Clusteradministrationsteam wäre beispielsweise nicht auf ein separates Netzwerkteam angewiesen, das den Load-Balancer vorzeitig akquirieren, ausführen und konfigurieren könnte.
Anthos-Cluster in VMware konfigurieren automatisch virtuelle IP-Adressen (VIPs) auf dem Load-Balancer. Zum Zeitpunkt der Clustererstellung konfiguriert Anthos-Cluster in VMware den Load-Balancer mit VIPs für den Kubernetes API-Server, den Ingress-Dienst und die Add-ons des Clusters. Wenn Clients Dienste vom Typ LoadBalancer erstellen, konfiguriert Anthos-Cluster auf VMware automatisch die Service-VIPs auf dem Load-Balancer.
Abhängigkeiten zwischen Organisationen, Gruppen und Administratoren werden reduziert. Insbesondere ist die Gruppe, die einen Cluster verwaltet, weniger von der Gruppe abhängig, die das Netzwerk verwaltet.
Empfohlene Versionen
Wir empfehlen, für den gebündelten Load-Balancing-Modus vSphere 6.7 oder höher und Virtual Distributed Switch (VDS) 6.6 oder höher zu verwenden.
Wenn Sie möchten, können Sie auch ältere Versionen verwenden, die Installation ist dann jedoch weniger sicher. Die verbleibenden Abschnitte in diesem Thema enthalten weitere Informationen zu den Sicherheitsvorteilen der Verwendung von vspex 6.7+ und VDS 6.6+.
VLANs planen
Eine Anthos-Cluster auf VMware-Installation hat einen Administratorcluster und einen oder mehrere Nutzercluster. Beim gebündelten Load-Balancing-Modus empfehlen wir Ihnen dringend, dass die Cluster in separaten VLANs enthalten sind, insbesondere, dass sich Ihr Administratorcluster in einem eigenen VLAN befindet.
Wenn Ihr Administratorcluster sich in einem eigenen VLAN befindet, wird der Traffic der Steuerungsebene vom Traffic der Datenebene getrennt. Diese Trennung schützt die Steuerungsebenen von Administratorcluster und Nutzerclustern vor unbeabsichtigten Konfigurationsfehlern. Solche Fehler können beispielsweise zu Problemen wie einem Übertragungssturm aufgrund von Ebene-2-Schleifen im selben VLAN führen, oder zu in Konflikt stehenden IP-Adressen, die die gewünschte Trennung zwischen der Datenebene und der Steuerungsebene aufheben.
VM-Ressourcen für gebündeltes Load-Balancing bereitstellen (Seesaw)
Mit einem gebündelten Load-Balancing stellen Sie die VM-CPU- und -Speicherressourcen gemäß dem erwarteten Netzwerktraffic bereit.
Der gebündelte Load-Balancer ist nicht speicherintensiv und kann in VMs mit 1 GB Arbeitsspeicher ausgeführt werden. Für eine höhere Netzwerkpaketrate ist jedoch mehr CPU erforderlich.
Die folgende Tabelle enthält CPU- und Arbeitsspeicherrichtlinien für die Bereitstellung von VMs. Da die Paketrate keine typische Messung der Netzwerkleistung darstellt, zeigt die Tabelle auch Richtlinien für die maximale Anzahl aktiver Netzwerkverbindungen. Außerdem wird angenommen, dass eine VM mit einer 10-Gbit/s-Verbindung und CPUs mit weniger als 70 % Kapazität laufen.
Wenn der gebündelte Load-Balancer im Hochverfügbarkeitsmodus (High Available, HA) ausgeführt wird, wird ein aktives und ein Sicherungspaar ausgeführt, um den gesamten Traffic über eine einzige VM zu führen.
Da die tatsächlichen Anwendungsfälle variieren, müssen diese Richtlinien auf der Grundlage Ihres tatsächlichen Traffics angepasst werden. Beobachten Sie Ihre Messwerte zu CPU und Paketraten, um die erforderlichen Änderungen vorzunehmen.
Wenn Sie die CPU und den Arbeitsspeicher für Seesaw-VMs ändern müssen, folgen Sie der Anleitung zum Upgrade von Load-Balancern. Sie können dieselbe Version des gebündelten Load-Balancers verwenden und nur die Anzahl der CPUs und die Arbeitsspeicherzuweisung ändern.
Für kleine Administratorcluster empfehlen wir 2 CPUs, für große Administratorcluster 4 CPUs.
| Speicher | CPU | Speicher | Paketrate (pps) | Maximale Anzahl aktiver Verbindungen |
|---|---|---|---|---|
| 20 GB | 1 (Nicht-Produktion) | 1 GB | 250k | 100 |
| 20 GB | 2 | 3 GB | 450k | 300 |
| 20 GB | 4 | 3 GB | 850k | 6.000 |
| 20 GB | 6 | 3 GB | 1,000k | 10.000 |
Beachten Sie, dass Sie nur eine einzelne CPU in einer Nicht-Produktionsumgebung bereitstellen müssen.
Virtuelle IP-Adressen reservieren
Unabhängig vom ausgewählten Load-Balancing-Modus müssen Sie mehrere virtuelle IP-Adressen (VIPs) reservieren, die Sie für das Load-Balancing verwenden möchten. Mit diesen VIPs können externe Clients Ihre Kubernetes API-Server, Ihre Dienste für eingehenden Traffic und Ihre Add-on-Dienste erreichen.
Sie müssen eine Gruppe von VIPs für Ihren Administratorcluster und eine Reihe von VIPs für jeden Nutzercluster reservieren, den Sie erstellen möchten. Für einen bestimmten Cluster müssen sich diese VIPs im selben VLAN wie die Clusterknoten und die Seesaw-VMs für diesen Cluster befinden.
Eine Anleitung zum Reservieren von VIPs finden Sie unter Administratorcluster erstellen.
Knoten-IP-Adressen reservieren
Im gebündelten Load-Balancing-Modus können Sie statische IP-Adressen für Ihre Clusterknoten angeben oder Ihre Clusterknoten können die IP-Adressen von einem DHCP-Server abrufen.
Wenn Ihre Clusterknoten statische IP-Adressen haben sollen, legen Sie genügend Adressen für die Knoten im Administratorcluster und die Knoten in allen Nutzerclustern fest, die Sie erstellen möchten. Informationen darüber, wie viele Knoten-IP-Adressen Sie reservieren können, erhalten Sie unter Administratorcluster erstellen.
IP-Adressen für Seesaw-VMs reservieren
Legen Sie als Nächstes IP-Adressen für die VMs fest, auf denen Ihre Seesaw-Load-Balancer ausgeführt werden.
Die Anzahl der Adressen, die Sie reservieren, hängt davon ab, ob Sie Hochverfügbarkeits-Load-Balancer (HA) oder Nicht-HA-Seesaw-Load-Balancer erstellen möchten.
Fall 1: HA-Seesaw-Load-Balancer
Legen Sie für Ihren Administratorcluster zwei IP-Adressen für zwei verschiedene VMs fest. Legen Sie auch für Ihren Administratorcluster eine einzelne Master-IP-Adresse für das Paar von Seesaw-VMs fest. Alle drei Adressen müssen sich im selben VLAN befinden wie die Knoten des Administratorclusters.
Legen Sie für jeden Nutzercluster, den Sie erstellen möchten, zwei IP-Adressen für ein Paar von Seesaw-VMs fest. Legen Sie auch für jeden Nutzercluster eine einzelne Master-IP-Adresse für das Paar der Seesaw-VMs fest. Für einen bestimmten Nutzercluster müssen sich alle drei Adressen im selben VLAN wie die Knoten des Nutzerclusters befinden.
Fall 2: Nicht-HA-Seesaw-Load-Balancer
Legen Sie für Ihren Administratorcluster eine IP-Adresse für eine Seesaw-VM bereit. Legen Sie auch für Ihren Administratorcluster eine Master-IP für den Seesaw-Load-Balancer fest. Beide Adressen müssen sich im selben VLAN wie die Knoten des Administratorclusters befinden.
Legen Sie für jeden Nutzercluster, den Sie erstellen möchten, eine IP-Adresse für eine Seesaw-VM fest. Legen Sie außerdem für jeden Nutzercluster eine Master-IP-Adresse für den Seesaw-Load-Balancer fest. Beide Adressen müssen sich im selben VLAN befinden wie die Nutzerclusterknoten.
Portgruppen planen
Jede Ihrer Seesaw-VMs hat zwei Netzwerkschnittstellen. Eine dieser Netzwerkschnittstellen ist mit VIPs konfiguriert. Die andere Netzwerkschnittstelle wird mit einer IP-Adresse konfiguriert, die aus einer von Ihnen bereitgestellten IP-Blockdatei stammt.
Bei einer einzelnen Seesaw-VM können die beiden Netzwerkschnittstellen mit derselben vSphere-Portgruppe oder mit separaten Portgruppen verbunden werden. Wenn die Portgruppen getrennt sind, müssen sie sich im selben VLAN befinden.
Dieses Thema bezieht sich auf zwei Portgruppen:
Portgruppe des Load-Balancers: Bei einer Seesaw-VM ist die mit VIPs konfigurierte Netzwerkschnittstelle mit dieser Portgruppe verbunden.
Portgruppe des Clusterknotens: Bei einer Seesaw-VM ist die Netzwerkschnittstelle, die mit einer IP-Adresse aus Ihrer IP-Blockdatei konfiguriert ist, mit dieser Portgruppe verbunden. Ihre Clusterknoten sind auch mit dieser Portgruppe verbunden.
Die Portgruppe des Load-Balancers und die Portgruppe des Clusterknotens können identisch sein. Wir empfehlen jedoch dringend, dass sie separat sind.
Das folgende Diagramm veranschaulicht die empfohlene Netzwerkkonfiguration für das Seesaw-Load-Balancing:
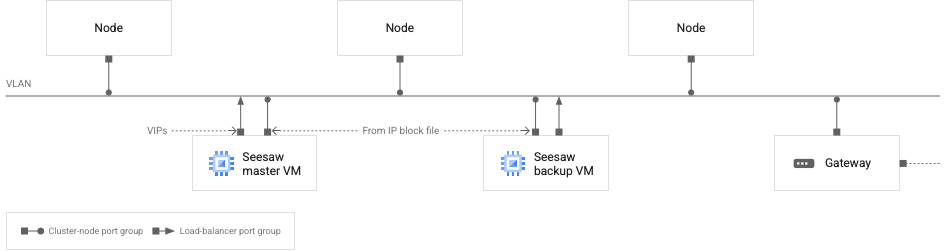 Seeaw-VMs und Clusterknoten in einem VLAN
Seeaw-VMs und Clusterknoten in einem VLAN
Das vorherige Diagramm stellt einen einzelnen Cluster dar, entweder einen Administrator- oder einen Nutzercluster. Jeder Cluster sollte sich in einem eigenen VLAN befinden.
Im Diagramm sehen Sie die folgenden Merkmale des Netzwerks:
Es gibt zwei Seesaw-VMs, einen Master und eine Sicherung.
Die Seesaw-VMs befinden sich im selben VLAN wie die Clusterknoten.
Die Sicherungs-Seesaw-VM hat zwei Netzwerkschnittstellen. Eine der Schnittstellen wird mit einer IP-Adresse aus Ihrer Seesaw-IP-Blockdatei konfiguriert. Die andere Schnittstelle ist nicht mit IP-Adressen konfiguriert.
Die Master-Seesaw-VM hat zwei Netzwerkschnittstellen. Eine der Schnittstellen wird mit einer IP-Adresse aus Ihrer Seesaw-IP-Blockdatei konfiguriert. Die andere Schnittstelle wird mit VIPs konfiguriert.
Jede Seesaw-VM hat eine Netzwerkschnittstelle, die mit der Load-Balancer-Portgruppe verbunden ist. Alle anderen Netzwerkschnittstellen im Diagramm sind mit der Portgruppe des Clusterknotens verbunden.
Alle IP-Adressen, einschließlich VIPs, die auf den im Diagramm angezeigten Netzwerkschnittstellen konfiguriert sind, müssen an das VLAN weitergeleitet werden können.
Bei einem Administratorcluster ist die VIPs-Schnittstelle auf der Seesaw-Master-VM mit den folgenden IP-Adressen konfiguriert:
- VIP für die Master-Seesaw-VM des Administratorclusters
- Administratorcluster-Add-on-VIP
- VIP der Steuerungsebene für den Administratorcluster
- VIPs der Steuerungsebene für alle zugehörigen Nutzercluster
- VIPs für Dienste vom Typ "LoadBalancer" im Administratorcluster
Bei einem Nutzercluster wird die VIP-Schnittstelle auf der Seesaw-Master-VM mit den folgenden IP-Adressen konfiguriert:
- VIP für die Master-Seesaw-VM des Nutzerclusters
- Ingress-VIP des Nutzerclusters
- VIPs für Dienste vom Typ "LoadBalancer", die im Nutzercluster ausgeführt werden
IP-Blockdateien erstellen
Geben Sie für jeden Cluster, den Sie erstellen möchten, die Adressen an, die Sie für Ihre Seesaw-VMs in einer IP-Blockdatei ausgewählt haben. Diese IP-Blockdatei ist für Ihre Load-Balancer-VMs bestimmt, nicht für Ihre Clusterknoten. Wenn Sie für Ihre Clusterknoten statische IP-Adressen verwenden möchten, müssen Sie für diese Adressen eine separate IP-Blockdatei erstellen. Hier ein Beispiel für eine IP-Blockdatei, die zwei IP-Adressen für Seesaw-VMs angibt:
blocks:
- netmask: "255.255.255.0"
gateway: "172.16.20.1"
ips:
- ip: "172.16.20.18"
hostname: "seesaw-vm-1"
- ip: "172.16.20.19"
hostname: "seesaw-vm-2"
Ihre Konfigurationsdateien eingeben
Bereiten Sie eine Konfigurationsdatei für jeden Ihrer Cluster vor: einen Administratorcluster und einen oder mehrere Nutzercluster.
Legen Sie in der Konfigurationsdatei für einen bestimmten Cluster loadBalancer.kind auf "Seesaw" fest.
Füllen Sie unter loadBalancer den Abschnitt seesaw aus:
loadBalancer:
kind: Seesaw
seesaw:
ipBlockFilePath::
vrid:
masterIP:
cpus:
memoryMB:
vCenter:
networkName:
enableha:
antiAffinityGroups:
enabled:
seesaw.ipBlockFilePath
String. Legen Sie hier den Pfad der IP-Blockdatei für Ihre Seesaw-VMs fest. Beispiel:
loadBalancer:
seesaw:
ipBlockFilePath: "admin-seesaw-ipblock.yaml"
seesaw.vrid
Integer. Die virtuelle Router-ID Ihrer Seesaw-VM. Diese Kennung muss in einem VLAN einmalig sein. Gültiger Bereich ist 1 – 255. Beispiel:
loadBalancer:
seesaw:
vrid: 125
seesaw.masterIP
String. Die Master-IP-Adresse des Seesaw-Load-Balancers. Beispiel:
loadBalancer:
seesaw:
masterIP: 172.16.20.21
seesaw.cpus
Integer. Die Anzahl der CPUs für jede Seesaw-VM. Beispiel:
loadBalancer:
seesaw:
cpus: 4
seesaw.memoryMB
Integer. Die Anzahl der Megabyte des Arbeitsspeichers für jede Seesaw-VM. Beispiel:
loadBalancer:
seesaw:
memoryMB: 3072
seesaw.vCenter.networkName
String. Der Name des Netzwerks, das Ihre Seesaw-VMs enthält. Wenn nicht festgelegt, wird dasselbe Netzwerk wie der Cluster verwendet. Beispiel:
loadBalancer:
seesaw:
vCenter:
networkName: "my-seesaw-network"
seesaw.enableHA
Boolescher Wert. Wenn Sie einen hochverfügbaren Seesaw-Load-Balancer erstellen möchten, legen Sie für dieses Feld true fest. Andernfalls legen Sie false fest. Beispiel:
loadBalancer:
seesaw:
enableHA: true
Wenn Sie enableha auf true setzen, müssen Sie MAC-Lernen aktivieren.
seesaw.antiAffinityGroups.enabled
Wenn Sie eine Anti-Affinitätsregel auf Ihre Seesaw-VMs anwenden möchten, setzen Sie den Wert von seesaw.antiAffinityGroups.enabled auf true. Andernfalls setzen Sie den Wert auf false. Der Standardwert ist true. Der empfohlene Wert ist true, damit Ihre Seesaw-VMs nach Möglichkeit auf verschiedenen physischen Hosts platziert werden. Beispiel:
loadBalancer:
seesaw
antiAffinityGroups:
enabled: true
MAC-Lernen oder promiskuitiver Modus (nur HA) aktivieren
Wenn Sie einen Nicht-HA-Seesaw-Load-Balancer einrichten, können Sie diesen Abschnitt überspringen.
Wenn Sie loadBalancer.seesaw.disableVRRPMAC auf „wahr“ gesetzt haben, ist die MAC-Lernkonfiguration nicht erforderlich. Ihr Netzwerk muss jedoch IP-Failover mit Gratuitous ARP unterstützen.
Siehe Konfigurationsdatei für Nutzercluster.
Wenn Sie einen HA-Seesaw-Load-Balancer einrichten undloadBalancer.seesaw.disableVRRPMAC auf false gesetzt haben, müssen Sie eine Kombination aus MAC-Lernen, gefälschten Übertragungen und promiskuitivem Modus in Ihrer Load-Balancer-Portgruppe aktivieren.
Wie Sie diese Funktionen aktivieren, hängt vom verwendeten Schalter ab:
| Typ wechseln | Funktionen aktivieren | Auswirkungen auf die Sicherheit |
|---|---|---|
| vSphere 7.0 VDS |
Bei vSphere 7.0 mit HA müssen Sie für loadBalancer.seesaw.disableVRRPMAC den Wert true festlegen. MAC-Lernen wird nicht unterstützt.
|
|
| vSphere 6.7 mit VDS 6.6 |
Aktivieren Sie MAC-Lernen und gefälschte Übertragungen für den Load-Balancer mit folgendem Befehl: |
Minimal. Wenn die Portgruppe des Load-Balancers nur mit Ihren Seesaw-VMs verbunden ist, können Sie das MAC-Lernen auf Ihre vertrauenswürdigen Seesaw-VMs beschränken. |
vSphere 6.5 oder vSphere Version 6.7 mit einer VDS-Version vor 6.6 |
Aktivieren Sie den promiskuitiven Modus und gefälschte Übertragungen für die Portgruppe des Load-Balancers. Verwenden Sie auf der Portgruppenseite auf dem Tab Networking (Netzwerk) die vSphere Benutzeroberfläche: Edit Settings -> Security (Einstellungen bearbeiten -> Sicherheit). | Alle VMs in der Portgruppe des Load-Balancers befinden sich im promiskuitiven Modus. So kann jede VM in der Portgruppe des Load-Balancers den gesamten Traffic sehen. Wenn die Portgruppe des Load-Balancers nur mit Ihren Seesaw-VMs verbunden ist, können nur die VMs den gesamten Traffic sehen. |
| Logischer NSX-T-Schalter | Aktivieren Sie MAC-Lernen für den logischen Switch. | vSphere unterstützt nicht das Erstellen von zwei logischen Switches in derselben Ebene-2-Domain. Die Seesaw-VMs und die Clusterknoten müssen sich also auf demselben logischen Switch befinden. Dies bedeutet, dass MAC-Lernen für alle Clusterknoten aktiviert ist. Ein Angreifer kann möglicherweise einen MAC-Spoof durch das Ausführen autorisierter Pods im Cluster erreichen. |
| vSphere-Standard-Switch | Aktivieren Sie den promiskuitiven Modus und gefälschte Übertragungen für die Portgruppe des Load-Balancers. Verwenden Sie auf jedem ESXI-Host die vSphere-Benutzeroberfläche: Configure -> Virtual switches -> Standard Switch -> Edit Setting on the port group -> Security (Konfigurieren -> Virtuelle Switches -> Standard-Switch -> Einstellung für die Portgruppe bearbeiten -> Sicherheit). | Alle VMs in der Portgruppe des Load-Balancers befinden sich im promiskuitiven Modus. So kann jede VM in der Portgruppe des Load-Balancers den gesamten Traffic sehen. Wenn die Portgruppe des Load-Balancers nur mit Ihren Seesaw-VMs verbunden ist, können nur die VMs den gesamten Traffic sehen. |
Preflight-Prüfung für die Konfigurationsdatei ausführen
Nachdem Sie die IP-Blockdateien und die Konfigurationsdatei des Administratorclusters erstellt haben, führen Sie eine Preflight-Prüfung für Ihre Konfigurationsdatei aus:
gkectl check-config --config [ADMIN_CONFIG_FILE]
Dabei ist [ADMIN_CONFIG_FILE] der Pfad Ihrer Administratorcluster-Konfigurationsdatei.
Für die Konfigurationsdatei des Nutzerclusters müssen Sie die kubeconfig-Datei des Administratorclusters in den Befehl einschließen:
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] check-config --config [USER_CONFIG_FILE]
Dabei ist [ADMIN_CLUSTER_KUBECONFIG] der Pfad der kubeconfig-Datei Ihres Administratorclusters.
Wenn die Preflight-Prüfung fehlschlägt, nehmen Sie bei Bedarf Anpassungen an Ihrer Clusterkonfigurationsdatei und Ihren IP-Blockdateien vor. Führen Sie dann die Preflight-Prüfung noch einmal aus.
Betriebssystem-Images hochladen
Führen Sie den folgenden Befehl aus, um Betriebssystem-Images in Ihre vSphere Umgebung hochzuladen:
gkectl prepare --config [ADMIN_CONFIG_FILE]
Dabei ist [ADMIN_CONFIG_FILE] der Pfad Ihrer Administratorcluster-Konfigurationsdatei.
Administratorcluster erstellen, der das gebündelte Load-Balancing verwendet
Erstellen und konfigurieren Sie die VMs für den Load-Balancer des Administratorclusters:
gkectl create loadbalancer --config [CONFIG_FILE]
Dabei ist [CONFIG_FILE] der Pfad Ihrer Administratorcluster-Konfigurationsdatei.
Erstellen Sie den Administratorcluster:
gkectl create admin --config [CONFIG_FILE]
Dabei ist [CONFIG_FILE] der Pfad Ihrer Administratorcluster-Konfigurationsdatei.
Nutzercluster erstellen, der den gebündelten Load-Balancer verwendet
Erstellen und konfigurieren Sie die VMs für den Load-Balancer des Nutzerclusters:
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] create loadbalancer --config [CONFIG_FILE]
Nutzercluster erstellen:
gkectl --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] create cluster --config [CONFIG_FILE]
wobei [ADMIN_CLUSTER_KUBECONFIG] der Pfad der kubeconfig-Datei für Ihren Administratorcluster und [CONFIG_FILE] der Pfad Ihrer Nutzercluster-Konfigurationsdatei ist.
Leistungs- und Lasttests
Der Download-Durchsatz Ihrer Anwendung wird linear mit der Anzahl der Back-Ends skaliert. Dies liegt daran, dass die Back-Ends mithilfe von Direct Server Return Antworten direkt an die Clients senden und dabei den Load-Balancer umgehen.
Im Gegensatz dazu ist der Uploaddurchsatz Ihrer Anwendung durch die Kapazität der einen Seesaw-VM begrenzt, die das Load-Balancing ausführt.
Anwendungen variieren in der benötigten CPU- und Arbeitsspeichermenge. Daher ist es äußerst wichtig, dass Sie einen Lasttest ausführen, bevor Sie mit der Bereitstellung einer großen Anzahl von Clients beginnen.
Tests haben ergeben, dass eine einzelne Seesaw-VM mit 6 CPUs und 3 GB Arbeitsspeicher 10 GB/s (Leitungsrate) zum Hochladen von Datenverkehr mit 10 K gleichzeitigen TCP-Verbindungen verarbeiten kann. Es ist jedoch wichtig, dass Sie einen eigenen Lasttest ausführen, wenn Sie eine große Anzahl gleichzeitiger TCP-Verbindungen unterstützen möchten.
Skalierungslimits
Beim gebündelten Load-Balancing sind die Skalierungsmöglichkeiten Ihres Clusters begrenzt. Die Anzahl der Knoten in Ihrem Cluster ist begrenzt. Die Anzahl der Dienste, die auf Ihrem Load-Balancer konfiguriert werden können, ist begrenzt. Außerdem gibt es eine Beschränkung für Systemdiagnosen. Die Anzahl der Systemdiagnosen hängt sowohl von der Anzahl der Knoten als auch von der Anzahl der Dienste ab.
Ab Version 1.3.1 hängt die Anzahl der Systemdiagnosen von der Anzahl der Knoten und der Anzahl der lokalen Dienste mit Traffic ab. Ein lokaler Trafficdienst ist ein Dienst, dessen externalTrafficPolicy auf "Local" gesetzt ist.
| Version 1.3.0 | Version 1.3.1 und höher | |
|---|---|---|
| Maximale Dienste (S) | 100 | 500 |
| Maximale Knoten (N) | 100 | 100 |
| Maximale Systemdiagnosen | S * N <= 10.000 | N + L * N <= 10.000, wobei L die Anzahl der lokalen Trafficdienste ist |
Beispiel: In Version 1.3.1 gehen wir davon aus, dass Sie 100 Knoten und 99 lokale Dienste für Traffic haben. Dann beträgt die Anzahl der Systemdiagnosen 100 + 99 * 100 = 10.000, was innerhalb des Limits von 10.000 liegt.
Load-Balancer für den Administratorcluster aktualisieren
Ab Version 1.4 werden Load-Balancer zusammen mit dem Cluster aktualisiert. Sie müssen keinen anderen Befehl ausführen, um die Load-Balancer separat zu aktualisieren. Sie können aber weiterhin gkectl upgrade loadbalancer unten verwenden, um einige Parameter zu aktualisieren.
Sie können CPUs und Arbeitsspeicher für Ihre Seesaw-VMs aktualisieren. Erstellen Sie eine neue Konfigurationsdatei wie im folgenden Beispiel und legen Sie CPUs und Arbeitsspeicher für Ihre Seesaw-VMs fest. Wenn Sie sie leer lassen, bleiben sie unverändert. Wenn "bundlePath" festgelegt ist, wird der Load-Balancer auf den im Bundle angegebenen Typ aktualisiert.
Beispiel:
apiVersion: v1
kind: AdminCluster
bundlePath:
loadBalancer:
kind: Seesaw
seesaw:
cpus: 3
memoryMB: 3072
Führen Sie dann den folgenden Befehl aus, um den Load-Balancer zu aktualisieren:
gkectl upgrade loadbalancer --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --config [ADMIN_CLUSTER_CONFIG] --admin-cluster
Dabei gilt:
[ADMIN_CLUSTER_KUBECONFIG] ist die kubeconfig-Datei für Ihren Administratorcluster.
[ADMIN_CLUSTER_CONFIG] ist die von Ihnen erstellte Konfigurationsdatei des Administratorclusters.
Während der Aktualisierung eines Load-Balancers kommt es zu einer Ausfallzeit. Wenn für den Load-Balancer Hochverfügbarkeit aktiviert ist, beträgt die maximale Ausfallzeit zwei Sekunden.
Load-Balancer für einen Nutzercluster aktualisieren
Ab Version 1.4 werden Load-Balancer zusammen mit dem Cluster aktualisiert. Sie müssen keinen anderen Befehl ausführen, um die Load-Balancer separat zu aktualisieren. Sie können aber weiterhin gkectl upgrade loadbalancer unten verwenden, um einige Parameter zu aktualisieren.
Sie können CPUs und Arbeitsspeicher für Ihre Seesaw-VMs aktualisieren. Erstellen Sie eine neue Konfigurationsdatei wie im folgenden Beispiel und legen Sie CPUs und Arbeitsspeicher für Ihre Seesaw-VMs fest. Wenn Sie sie leer lassen, bleiben sie unverändert. Wenn gkeOnPremVersion festgelegt ist, wird der Load-Balancer auf die von dieser Version angegebene Version aktualisiert.
Beispiel:
apiVersion: v1
kind: UserCluster
name: cluster-1
gkeOnPremVersion:
loadBalancer:
kind: Seesaw
seesaw:
cpus: 4
memoryMB: 3072
Führen Sie dann den folgenden Befehl aus, um den Load-Balancer zu aktualisieren:
gkectl upgrade loadbalancer --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --config [USER_CLUSTER_CONFIG]
Dabei gilt:
[ADMIN_CLUSTER_KUBECONFIG] ist die kubeconfig-Datei für Ihren Administratorcluster.
[USER_CLUSTER_CONFIG] ist die von Ihnen erstellte Nutzer-Konfigurationsdatei.
[CLUSTER_NAME] ist der Name des Clusters, der aktualisiert wird.
Seesaw-Logs ansehen
Der gebündelte Seesaw-Load-Balancer speichert Logdateien in den Seesaw-VMs in /var/log/seesaw/. Die wichtigste Logdatei ist seesaw_engine.INFO.
Bei v1.6 werden Logs, sofern Stackdriver aktiviert ist, auch in Cloud hochgeladen. Sie können sie unter der Ressource "anthos_l4lb" ansehen. Zum Deaktivieren des Log-Uploads können Sie eine SSH-Verbindung zur VM herstellen und folgenden Befehl ausführen:
sudo systemctl disable --now docker.fluent-bit.service
Informationen zu Ihren Seesaw-VMs ansehen
Sie können Informationen über Ihre Seesaw-VMs für einen Cluster von der benutzerdefinierten Ressource "SeesawGroup" abrufen.
Sehen Sie sich die benutzerdefinierte Ressource "SeesawGroup" für einen Cluster an:
kubectl --kubeconfig [CLUSTER_KUBECONFIG] get seesawgroups -n kube-system -o yaml
Dabei ist [CLUSTER_KUBECONFIG] der Pfad der kubeconfig-Datei für den Cluster.
Die Ausgabe enthält das Feld isReady, das angibt, ob die VMs für die Verarbeitung des Traffics bereit sind. Die Ausgabe zeigt auch die Namen und IP-Adressen der Seesaw-VMs an und welche VM die primäre ist:
apiVersion: seesaw.gke.io/v1alpha1
kind: SeesawGroup
metadata:
...
name: seesaw-for-cluster-1
namespace: kube-system
...
spec: {}
status:
machines:
- hostname: cluster-1-seesaw-1
ip: 172.16.20.18
isReady: true
lastCheckTime: "2020-02-25T00:47:37Z"
role: Master
- hostname: cluster-1-seesaw-2
ip: 172.16.20.19
isReady: true
lastCheckTime: "2020-02-25T00:47:37Z"
role: Backup
Seesaw-Messwerte ansehen
Der gebündelte Seesaw-Load-Balancer liefert die folgenden Messwerte:
- Durchsatz pro Dienst oder Knoten
- Paketrate pro Dienst oder Knoten
- Aktive Verbindungen pro Dienst oder Knoten
- CPU- und Arbeitsspeichernutzung
- Anzahl fehlerfreier Back-End-Pods pro Dienst
- Welche VM ist die primäre und welche dient als Sicherung
- Betriebszeit
Ab Version v1.6 werden diese Messwerte mit Stackdriver in die Cloud hochgeladen. Sie können sie unter der Monitoringressource von "anthos_l4lb" ansehen.
Sie können auch alle Monitoring- und Dashboard-Lösungen Ihrer Wahl verwenden, solange sie das Prometheus-Format unterstützen.
Load-Balancer löschen
Wenn Sie einen Cluster löschen, der gebündeltes Load-Balancing verwendet, sollten Sie auch die Seesaw-VMs für diesen Cluster löschen. Löschen Sie dazu die Seesaw-VMs in der vSphere-Benutzeroberfläche.
Alternativ können Sie ab Version 1.4.2 gkectl ausführen und Konfigurationsdateien übergeben, um den gebündelten Load-Balancer und dessen Gruppendatei zu löschen.
Führen Sie für Administratorcluster den folgenden Befehl aus:
gkectl delete loadbalancer --config [ADMIN_CONFIG_FILE] --seesaw-group-file [GROUP_FILE]
Führen Sie für Nutzercluster den folgenden Befehl aus:
gkectl delete loadbalancer --config [CLUSTER_CONFIG_FILE] --seesaw-group-file [GROUP_FILE] --kubeconfig [ADMIN_CLUSTER_KUBECONFIG]
Dabei gilt:
[ADMIN_CONFIG_FILE] ist die Konfigurationsdatei für den Administratorcluster
[CLUSTER_CONFIG_FILE] ist die Konfigurationsdatei für den Nutzercluster
[ADMIN_CLUSTER_KUBECONFIG] ist die Administratordatei
kubeconfig.[GROUP_FILE] ist die Seesaw-Gruppendatei. Der Name der Gruppendatei hat das Format
seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml.
Versionen vor 1.4.2
In Versionen vor 1.4.2 können Sie alternativ diesen Befehl ausführen, wodurch die Seesaw-VMs und die Seesaw-Gruppendatei gelöscht werden:
gkectl delete loadbalancer --config vsphere.yaml --seesaw-group-file [GROUP_FILE]
Dabei gilt:
[GROUP_FILE] ist die Seesaw-Gruppendatei. Die Gruppendatei befindet sich auf Ihrer Admin-Workstation neben
config.yaml. Der Name der Gruppendatei hat das Formatseesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml.vsphere.yamlist eine Datei mit den folgenden Informationen zu Ihrem vCenter-Server:
vcenter:
credentials:
address:
username:
password:
datacenter:
cacertpath:
Problembehebung
SSH-Verbindung zu einer Seesaw-VM herstellen
Gelegentlich möchten Sie möglicherweise eine SSH-Verbindung zu einer Seesaw-VM zur Fehlerbehebung oder Fehlerbehebung herstellen.
SSH-Schlüssel abrufen
Wenn Sie den Cluster bereits erstellt haben, führen Sie die folgenden Schritte aus, um den SSH-Schlüssel abzurufen:
Rufen Sie das Secret
seesaw-sshaus dem Cluster ab. Rufen Sie den SSH-Schlüssel des Secret ab und führen Sie eine Base64-Decodierung durch. Speichern Sie den decodierten Schlüssel in einer temporären Datei:kubectl --kubeconfig [CLUSTER_KUBECONFIG] get -n kube-system secret seesaw-ssh -o \ jsonpath='{@.data.seesaw_ssh}' | base64 -d | base64 -d > /tmp/seesaw-ssh-keyDabei ist [CLUSTER_KUBECONFIG] die kubeconfig-Datei für Ihren Cluster.
Legen Sie die entsprechenden Berechtigungen für die Schlüsseldatei fest:
chmod 0600 /tmp/seesaw-ssh-key
Wenn Sie den Cluster bereits erstellt haben, führen Sie die folgenden Schritte aus, um den SSH-Schlüssel abzurufen:
Suchen Sie die Datei mit dem Namen
seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml.Die Datei wird als Gruppendatei bezeichnet und befindet sich neben
config.yaml.Außerdem wird mit
gkectl create loadbalancerder Speicherort der Gruppendatei ausgegeben.Ermitteln Sie in der Datei den Wert
credentials.ssh.privateKeyund führen Sie eine base64-Decodierung durch. Speichern Sie den decodierten Schlüssel in einer temporären Datei:cat seesaw-for-[CLUSTER_NAME]-[IDENTIFIER].yaml | grep privatekey | sed 's/ privatekey: //g' \ | base64 -d > /tmp/seesaw-ssh-key
Legen Sie die entsprechenden Berechtigungen für die Schlüsseldatei fest:
chmod 0600 /tmp/seesaw-ssh-key
Jetzt können Sie eine SSH-Verbindung zur Seesaw-VM herstellen:
ssh -i /tmp/seesaw-ssh-key ubuntu@[SEESAW_IP]
Dabei ist [SEESAW_IP] die IP-Adresse der Seesaw-VM.
Snapshots abrufen
Sie können Snapshots für Seesaw-VMs mit dem Befehl gkectl diagnose snapshot zusammen mit dem Flag --scenario erfassen.
Wenn Sie --scenario auf all oder all-with-logs setzen, enthält die Ausgabe Seesaw-Snapshots zusammen mit anderen Snapshots.
Wenn Sie --scenario auf seesaw setzen, enthält die Ausgabe nur Seesaw-Snapshots.
Beispiele:
gkectl diagnose snapshot --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --scenario seesaw
Dabei ist [ADMIN_CLUSTER_KUBECONFIG] die Datei "kubeconfig" für Ihren Administratorcluster.
gkectl diagnose snapshot --kubeconfig [ADMIN_CLUSTER_KUBECONFIG] --cluster-name [CLUSTER_NAME] --scenario seesaw
gkectl diagnose snapshot --seesaw-group-file [GROUP_FILE] --scenario seesaw
Dabei ist [GROUP_FILE] der Pfad der Gruppendatei für den Cluster, z. B. seesaw-for-gke-admin-xxxxxx.yaml.
Bekannte Probleme
Cisco ACI funktioniert nicht mit Direct Server Return (DSR)
Seesaw wird im DSR-Modus ausgeführt und funktioniert aufgrund des IP-Lernens auf Datenebene standardmäßig nicht in Cisco ACI. Eine mögliche Problemumgehung über die Anwendungs-Endpunktgruppe finden Sie hier.