En este tema, se muestra cómo exportar registros y métricas de un clúster de usuario de clústeres de Anthos en AWS a Cloud Logging y Cloud Monitoring.
Descripción general
Existen varias opciones para registrar y supervisar con clústeres de Anthos en AWS. Anthos se puede integrar a Cloud Logging y Cloud Monitoring. Debido a que Anthos está basado en Kubernetes de código abierto, muchas herramientas de código abierto y de terceros son compatibles.
Opciones de registro y supervisión
Tienes varias opciones de registro y supervisión para tu clúster de Anthos:
Implementa los agentes de Cloud Logging y Cloud Monitoring para supervisar y ver los registros de tus cargas de trabajo en Google Cloud Console. En este tema, se explica esta solución.
Usa herramientas de código abierto, como Prometheus, Grafana y Elasticsearch. En este tema, no se describe esta solución.
Usa soluciones de terceros como Datadog. En este tema, no se describe esta solución.
Cloud Logging y Cloud Monitoring
Con Anthos, Cloud Logging y Cloud Monitoring, puedes crear paneles, enviar alertas, supervisar y revisar registros de las cargas de trabajo que se ejecutan en tu clúster. Debes configurar los agentes de Cloud Logging y Cloud Monitoring para recopilar los registros y las métricas en tu proyecto de Google Cloud. Si no configuras estos agentes, los clústeres de Anthos en AWS no recopilan datos de registro ni supervisión.
Qué datos se recopilan
Cuando se configuran, los agentes recopilan registros y datos de métricas de tu clúster y las cargas de trabajo que se ejecutan en él. Estos datos se almacenan en tu proyecto de Google Cloud. El ID del proyecto se configura en el campo project_id en un archivo de configuración cuando instalas el servidor de reenvío.
Entre los datos recopilados, se incluyen los siguientes:
- Registros de los servicios del sistema en cada uno de los nodos trabajadores.
- Registros de aplicaciones para todas las cargas de trabajo que se ejecutan en el clúster.
- Métricas para los servicios del clúster y del sistema. Para obtener más información sobre métricas específicas, consulta Métricas de Anthos.
- Métricas de la aplicación para los pods, si tus aplicaciones están configuradas con los objetivos de recopilación de Prometheus y se anotan con la configuración, incluidos
prometheus.io/scrape,prometheus.io/pathyprometheus.io/port.
Los agentes pueden inhabilitarse en cualquier momento. Para obtener más información, consulta cómo hacer una limpieza. Los datos que recopilan los agentes se pueden administrar y borrar como cualquier otro dato de métrica y registro, como se describe en la documentación de Cloud Monitoring y Cloud Logging.
Los datos de registro se almacenan de acuerdo con las reglas de retención configuradas. La retención de datos de las métricas varía según el tipo.
Registra y supervisa componentes
Para exportar la telemetría a nivel de clúster desde los clústeres de Anthos en AWS a Google Cloud, debes implementar los siguientes componentes en tu clúster:
- Stackdriver Log Forwarder (stackdriver-log-forwarder-*). Un DaemonSet de Fluentbit que reenvía los registros de cada nodo de Kubernetes a Cloud Logging
- Agente de métricas de GKE (gke-metrics-agent-*). Un DaemonSet basado en OpenTelemetry Collector que recopila datos de métricas y los reenvía a Cloud Monitoring.
Los manifiestos para estos componentes se encuentran en el repositorio anthos-samples en GitHub.
Requisitos previos
Un proyecto de Google Cloud con facturación habilitada. Para obtener más información sobre los costos, consulta Precios de Google Cloud's operations suite.
El proyecto también debe tener habilitadas las API de Cloud Logging y Cloud Monitoring. Para habilitar estas API, ejecuta los siguientes comandos:
gcloud services enable logging.googleapis.com gcloud services enable monitoring.googleapis.comUn entorno de clústeres de Anthos en AWS, incluido el clúster de usuario registrado con Connect. Ejecuta el siguiente comando para verificar que tu clúster esté registrado.
gcloud container fleet memberships listSi tu clúster está registrado, Google Cloud CLI imprime el nombre y el ID del clúster.
NAME EXTERNAL_ID cluster-0 1abcdef-1234-4266-90ab-123456abcdefSi no ves tu clúster en la lista, consulta Conéctate a un clúster con Connect
Instala la herramienta de línea de comandos de
giten tu máquina.
Configura permisos para Google Cloud's operations suite
Los agentes de registro y supervisión usan Workload Identity de la flota para comunicarse con Cloud Logging y Cloud Monitoring. La identidad necesita permisos para escribir registros y métricas en tu proyecto. Para agregar los permisos, ejecuta los siguientes comandos:
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:PROJECT_ID.svc.id.goog[kube-system/stackdriver]" \
--role=roles/logging.logWriter
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:PROJECT_ID.svc.id.goog[kube-system/stackdriver]" \
--role=roles/monitoring.metricWriter
Reemplaza PROJECT_ID con el proyecto de Google Cloud.
Conéctate al host de bastión
Para conectarte a tus clústeres de Anthos en recursos de AWS, sigue estos pasos. Selecciona si tienes una VPC de AWS existente (o conexión directa a tu VPC) o si creaste una VPC dedicada cuando creaste tu servicio de administración.
VPC existente
Si tienes una conexión directa o de VPN con una VPC existente, omite la línea env HTTP_PROXY=http://localhost:8118 de los comandos en este tema.
VPC dedicada
Cuando creas un servicio de administración en una VPC dedicada, clústeres de Anthos alojados en AWS incluye un host de bastión en una subred pública.
Para conectarte al servicio de administración, realiza los siguientes pasos:
Cambia al directorio con tus clústeres de Anthos en la configuración de AWS. Creaste este directorio cuando instalaste el servicio de administración.
cd anthos-aws
Para abrir el túnel, ejecuta la secuencia de comandos
bastion-tunnel.sh. El túnel reenvía alocalhost:8118.Para abrir un túnel al host de bastión, ejecuta el siguiente comando:
./bastion-tunnel.sh -NLos mensajes del túnel SSH aparecen en esta ventana. Cuando estés listo para cerrar la conexión, detén el proceso mediante Control+C o cierra la ventana.
Abre una terminal nueva y cambia a tu directorio de
anthos-aws.cd anthos-aws
Verifica que puedas conectarte al clúster con
kubectl.env HTTPS_PROXY=http://localhost:8118 \ kubectl cluster-infoEl resultado incluye la URL para el servidor de API del servicio de administración.
Cloud Logging y Cloud Monitoring en nodos del plano de control
Con la versión 1.8.0 de los clústeres de Anthos alojados en AWS y las posteriores, Cloud Logging y Cloud Monitoring para los nodos del plano de control se pueden configurar de forma automática cuando se crean clústeres de usuario nuevos. Para habilitar Cloud Logging o Cloud Monitoring, propaga la sección controlPlane.cloudOperations de la configuración de AWSCluster.
cloudOperations:
projectID: PROJECT_ID
location: GC_REGION
enableLogging: ENABLE_LOGGING
enableMonitoring: ENABLE_MONITORING
Reemplaza lo siguiente:
PROJECT_ID: el ID de tu proyectoGC_REGION: es la región de Google Cloud en la que deseas almacenar los registros. Elige una región ubicada cerca de la región de AWS. Para obtener más información, consulta Ubicaciones globales: Regiones y zonas, por ejemplo,us-central1.ENABLE_LOGGING:trueofalse, si Cloud Logging está habilitado en nodos del plano de control.ENABLE_MONITORING:trueofalse, si Cloud Monitoring está habilitado en nodos del plano de control.
A continuación, sigue los pasos en Crea un clúster de usuario personalizado.
Cloud Logging y Cloud Monitoring en nodos trabajadores
Quita la versión anterior
Si configuraste una versión anterior de los agentes de Logging y Monitoring que incluyestackdriver-log-aggregator (Fluentd) ystackdriver-prometheus-k8s (Prometheus), es posible que quieras desinstalarlas antes de continuar.
Instala el servidor de reenvío de registros
En esta sección, instalarás Stackdriver Log Forwarder en tu clúster.
Desde el directorio
anthos-samples/aws-logging-monitoring/, cambia al directoriologging/.cd logging/Modifica el archivo
forwarder.yamlpara que coincida con la configuración de tu proyecto:sed -i "s/PROJECT_ID/PROJECT_ID/g" forwarder.yaml sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" forwarder.yaml sed -i "s/CLUSTER_LOCATION/GC_REGION/g" forwarder.yamlReemplaza lo siguiente:
PROJECT_ID: el ID de tu proyectoCLUSTER_NAME: El nombre de tu clúster, por ejemplo,cluster-0GC_REGION: es la región de Google Cloud en la que deseas almacenar los registros. Elige una región ubicada cerca de la región de AWS. Para obtener más información, consulta Ubicaciones globales: Regiones y zonas, por ejemplo,us-central1.
En función de tus cargas de trabajo, la cantidad de nodos en tu clúster y la cantidad de Pods por nodo, es posible que debas configurar las solicitudes de memoria y recursos de CPU (opcional). Para obtener más información, consulta las asignaciones de CPU y memoria recomendadas.
Desde el directorio
anthos-aws, usaanthos-gkepara cambiar el contexto al clúster de usuario.cd anthos-aws env HTTPS_PROXY=http://localhost:8118 \ anthos-gke aws clusters get-credentials CLUSTER_NAME
Reemplaza CLUSTER_NAME por el nombre de tu clúster de usuario.Crea la cuenta de servicio
stackdriversi no existe y, luego, implementa el servidor de reenvío de registros en el clúster.env HTTPS_PROXY=http://localhost:8118 \ kubectl create serviceaccount stackdriver -n kube-system env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f forwarder.yamlUsa
kubectlpara verificar que los Pods se hayan iniciado.env HTTPS_PROXY=http://localhost:8118 \ kubectl get pods -n kube-system | grep stackdriver-logDeberías ver un Pod de reenvío por nodo en un grupo de nodos. Por ejemplo, en un clúster de 6 nodos, deberías ver seis Pods de reenvío.
stackdriver-log-forwarder-2vlxb 2/2 Running 0 21s stackdriver-log-forwarder-dwgb7 2/2 Running 0 21s stackdriver-log-forwarder-rfrdk 2/2 Running 0 21s stackdriver-log-forwarder-sqz7b 2/2 Running 0 21s stackdriver-log-forwarder-w4dhn 2/2 Running 0 21s stackdriver-log-forwarder-wrfg4 2/2 Running 0 21s
Prueba el reenvío de registros
En esta sección, implementarás una carga de trabajo que contiene un servidor web HTTP básico con un generador de cargas en tu clúster. Luego, probarás que los registros estén presentes en Cloud Logging.
Antes de instalar esta carga de trabajo, puedes verificar los manifiestos para el servidor web y el generador de cargas.
Implementa el servidor web y el generador de cargas en el clúster.
env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/server/server.yaml env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/loadgen/loadgen.yamlPara verificar que puedas ver los registros de tu clúster en el panel de Cloud Logging, ve al Explorador de registros en Google Cloud Console:
Copia la consulta de muestra que aparece a continuación en el campo Compilador de consultas.
resource.type="k8s_container" resource.labels.cluster_name="CLUSTER_NAME"Reemplaza CLUSTER_NAME por el nombre del clúster.
Haga clic en Ejecutar consulta. Los registros de clústeres recientes deberían aparecer en Resultados de consultas.
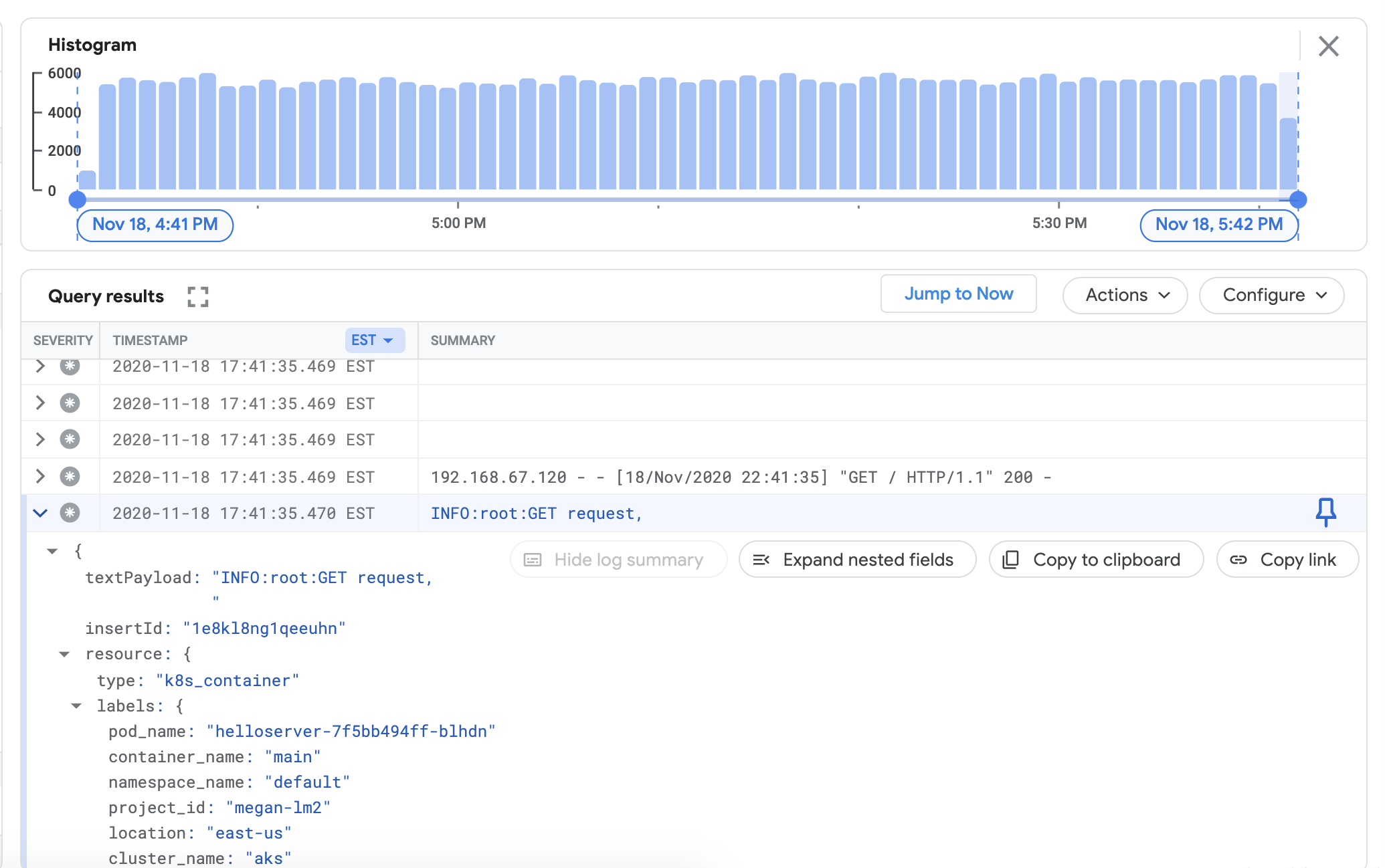
Una vez que hayas confirmado los registros en los resultados de la consulta, quita el generador de cargas y el servidor web.
env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/loadgen/loadgen.yaml env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/server/server.yaml
Instala el recopilador de métricas
En esta sección, instalarás un agente para enviar datos a Cloud Monitoring.
Desde el directorio
anthos-samples/aws-logging-monitoring/logging/, cambia al directorioanthos-samples/aws-logging-monitoring/monitoring/.cd ../monitoringModifica el archivo
gke-metrics-agent.yamlpara que coincida con la configuración de tu proyecto:sed -i "s/PROJECT_ID/PROJECT_ID/g" gke-metrics-agent.yaml sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" gke-metrics-agent.yaml sed -i "s/CLUSTER_LOCATION/GC_REGION/g" gke-metrics-agent.yamlReemplaza lo siguiente:
PROJECT_ID: el ID de tu proyectoCLUSTER_NAME: El nombre de tu clúster, por ejemplo,cluster-0GC_REGION: es la región de Google Cloud en la que deseas almacenar los registros. Elige una región ubicada cerca de la región de AWS. Para obtener más información, consulta Ubicaciones globales: Regiones y zonas, por ejemplo,us-central1.
En función de tus cargas de trabajo, la cantidad de nodos en tu clúster y la cantidad de Pods por nodo, es posible que debas configurar las solicitudes de memoria y recursos de CPU (opcional). Para obtener más información, consulta las asignaciones de CPU y memoria recomendadas.
Crea la cuenta de servicio
stackdriversi no existe y, luego, implementa el agente de métricas en tu clúster.env HTTPS_PROXY=http://localhost:8118 \ kubectl create serviceaccount stackdriver -n kube-system env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f gke-metrics-agent.yamlUsa la herramienta de
kubectlpara verificar que el Podgke-metrics-agentesté en ejecución.env HTTPS_PROXY=http://localhost:8118 \ kubectl get pods -n kube-system | grep gke-metrics-agentDeberías ver un Pod de agente por nodo en un grupo de nodos. Por ejemplo, en un clúster de 3 nodos, deberías ver tres Pods de agentes.
gke-metrics-agent-gjxdj 2/2 Running 0 102s gke-metrics-agent-lrnzl 2/2 Running 0 102s gke-metrics-agent-s6p47 2/2 Running 0 102s
Para verificar que las métricas de tu clúster se exporten a Cloud Monitoring, ve al Explorador de métricas en Google Cloud Console:
En el Explorador de métricas, haz clic en Editor de consultas y, luego, cópialo en el siguiente comando:
fetch k8s_container | metric 'kubernetes.io/anthos/otelcol_exporter_sent_metric_points' | filter resource.project_id == 'PROJECT_ID' && (resource.cluster_name =='CLUSTER_NAME') | align rate(1m) | every 1mReemplaza lo siguiente:
PROJECT_ID: el ID de tu proyectoCLUSTER_NAME: el nombre del clúster que usaste cuando se creó un clúster de usuario, por ejemplo,cluster-0.
Haz clic en Ejecutar consulta. Aparecerá la tasa de puntos de métrica enviados a Cloud Monitoring desde cada pod de
gke-metrics-agenten tu clúster.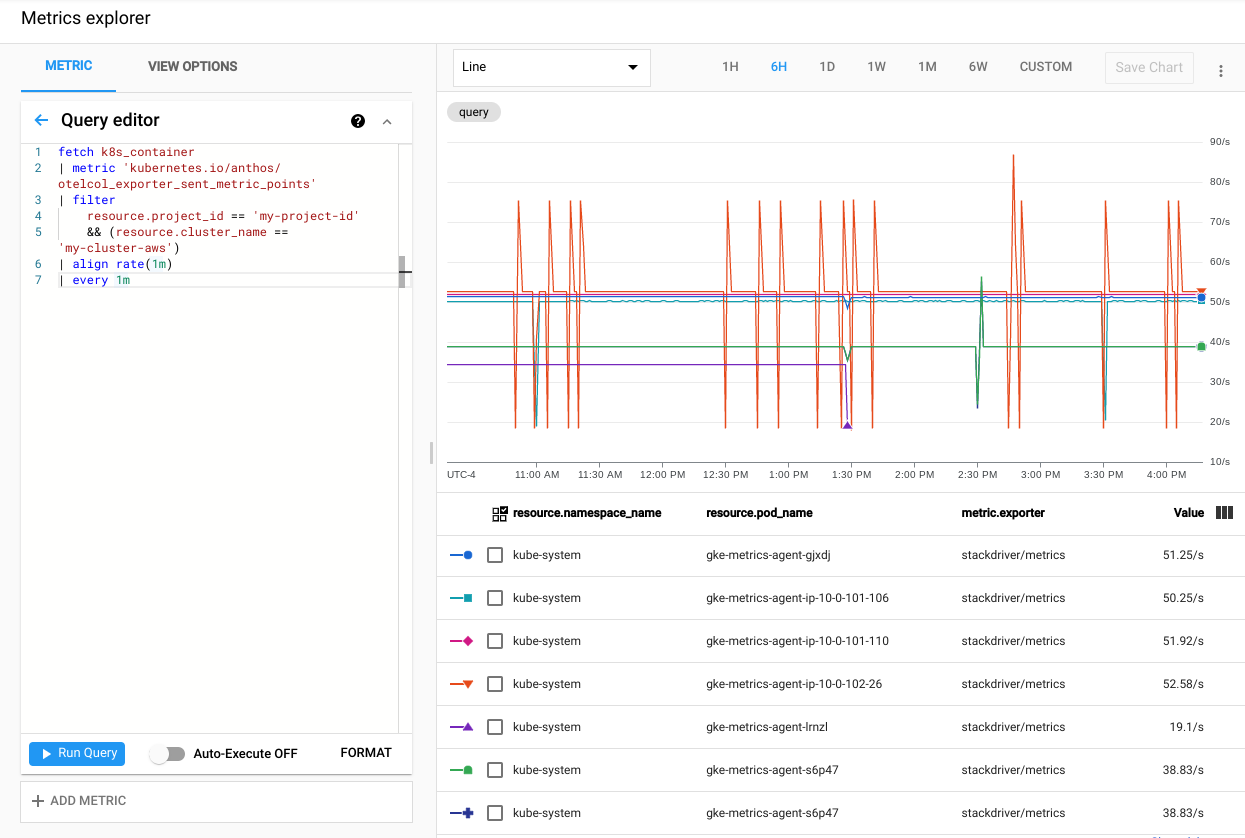
Estas son otras métricas que vale la pena probar:
kubernetes.io/anthos/container_memory_working_set_bytes: Uso de memoria del contenedor;kubernetes.io/anthos/container_cpu_usage_seconds_total: Uso de CPU de los contenedores;kubernetes.io/anthos/apiserver_aggregated_request_total: Recuento de solicitudes de kube-apiserver; solo está disponible si Cloud Monitoring está habilitado en el plano de control.
Para obtener una lista completa de las métricas disponibles, consulta Métricas de Anthos. Para obtener información sobre cómo usar la interfaz de usuario, consulta el Explorador de métricas.
Crea un panel en Cloud Monitoring
En esta sección, crearás un panel de Cloud Monitoring que supervisa el estado del contenedor en tu clúster.
Desde el directorio
anthos-samples/aws-logging-monitoring/monitoring/, cambia al directorioanthos-samples/aws-logging-monitoring/monitoring/dashboards.cd dashboardsReemplaza las instancias de la string
CLUSTER_NAMEenpod-status.jsonpor el nombre del clúster.sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" pod-status.jsonReemplaza
CLUSTER_NAMEpor el nombre del clúster.Ejecuta el siguiente comando para crear un panel personalizado con el archivo de configuración:
gcloud monitoring dashboards create --config-from-file=pod-status.jsonPara verificar que se creó tu panel, ve a Paneles de Cloud Monitoring en Google Cloud Console.
Abre el panel recién creado con un nombre en el formato
CLUSTER_NAME (Anthos cluster on AWS) pod status.
Realice una limpieza
En esta sección, quitarás los componentes de registro y supervisión de tu clúster.
Borra el panel de supervisión en la vista de lista de paneles de Google Cloud Console. Para ello, haz clic en el botón Borrar asociado al nombre del panel.
Cambia al directorio
anthos-samples/aws-logging-monitoring/con el siguiente comando:cd anthos-samples/aws-logging-monitoringPara quitar todos los recursos creados en esta guía, ejecuta los siguientes comandos:
env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f logging/ env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f monitoring/
Asignaciones recomendadas de CPU y memoria
En esta sección, se incluyen la CPU recomendada y las asignaciones para los componentes individuales que se usan en los registros y la supervisión. En cada una de las siguientes tablas, se enumeran las solicitudes de CPU y memoria para un clúster con un rango de tamaños de nodos. Puedes configurar solicitudes de recursos para un componente en el archivo que aparece en la tabla.
Para obtener más información, consulta las prácticas recomendadas de Kubernetes sobre límites y solicitudes de recursos y la administración de recursos para contenedores.
De 1 a 10 nodos
| File | Recurso | Solicitudes de CPU | Límites de CPU | Solicitudes de memoria | Límites de memoria |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 30m | 100m | 50Mi | 500Mi |
logging/forwarder.yaml |
stackdriver-log-forwarder | 50m | 100m | 100Mi | 600Mi |
De 10 a 100 nodos
| File | Recurso | Solicitudes de CPU | Límites de CPU | Solicitudes de memoria | Límites de memoria |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 50m | 100m | 50Mi | 500Mi |
logging/forwarder.yaml |
stackdriver-log-forwarder | 60m | 100m | 100Mi | 600Mi |
Más de 100 nodos
| Archivo | Recurso | Solicitudes de CPU | Límites de CPU | Solicitudes de memoria | Límites de memoria |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 50m | 100m | 100Mi | N/A |
logging/forwarder.yaml |
stackdriver-log-forwarder | 60m | 100m | 100Mi | 600Mi |
Próximos pasos
Obtén información sobre Cloud Logging:
- Descripción general de Cloud Logging
- Usar el Explorador de registros
- Cómo compilar consultas para Cloud Logging
- Crea métricas basadas en registros