Finding the cause of errors that arise when training your model or getting predictions in the cloud can be challenging. This page describes how to find and debug problems you encounter in AI Platform Prediction. If you encounter problems with the machine learning framework that you are using, read the documentation for the machine learning framework instead.
Command-line tool
- ERROR: (gcloud) Invalid choice: 'ai-platform'.
This error means that you need to update gcloud. To update gcloud, run the following command:
gcloud components update- ERROR: (gcloud) unrecognized arguments: --framework=SCIKIT_LEARN.
This error means that you need to update gcloud. To update gcloud, run the following command:
gcloud components update- ERROR: (gcloud) unrecognized arguments: --framework=XGBOOST.
This error means that you need to update gcloud. To update gcloud, run the following command:
gcloud components update- ERROR: (gcloud) Failed to load model: Could not load the model: /tmp/model/0001/model.pkl. '\x03'. (Error code: 0)
This error means the wrong library was used to export the model. To correct this, re-export the model using the correct library. For example, export models of the form
model.pklwith thepicklelibrary and models of the formmodel.joblibwith thejobliblibrary.- ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.
This error means that you specified
jsonas the value of the--data-formatflag when submitting a batch prediction job. In order to use theJSONdata format, you must providetextas the value of the--data-formatflag.
Python versions
- ERROR: Bad model detected with error: "Failed to load model: Could not load the
- model: /tmp/model/0001/model.pkl. unsupported pickle protocol: 3. Please make
- sure the model was exported using python 2. Otherwise, please specify the
- correct 'python_version' parameter when deploying the model. Currently,
- 'python_version' accepts 2.7 and 3.5. (Error code: 0)"
- This error means a model file exported with Python 3 was deployed to an AI Platform Prediction model version resource with a Python 2.7 setting.
To resolve this:
- Create a new model version resource and set 'python_version' to 3.5.
- Deploy the same model file to the new model version resource.
The virtualenv command isn't found
If you got this error when you tried to activate virtualenv, one possible
solution is to add the directory containing virtualenv to your $PATH
environment variable. Modifying this variable enables you to use virtualenv
commands without typing their full file path.
First, install virtualenv by running the following command:
pip install --user --upgrade virtualenv
The installer prompts you to modify your $PATH environment
variable, and it provides the path to the virtualenv script. On macOS, this
looks similar to
/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin.
Open the file where your shell loads environment variables. Typically, this is
~/.bashrc or ~/.bash_profile in macOS.
Add the following line, replacing [VALUES-IN-BRACKETS] with the appropriate
values:
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
Finally, run the following command to load your updated .bashrc
(or .bash_profile) file:
source ~/.bashrc
Using job logs
A good first place to start troubleshooting is the job logs captured by Cloud Logging.
Logging for the different types of operation
Your logging experience varies by the type of operation as shown in the following sections.
Batch prediction logs
All of your batch prediction jobs are logged.
Online prediction logs
Your online prediction requests don't generate logs by default. You can enable Cloud Logging when you create your model resource:
gcloud
Include the --enable-logging flag when you run
gcloud ai-platform models create.
Python
Set onlinePredictionLogging to True in the
Model resource you use
for your call to
projects.models.create.
Finding the logs
Your job logs contain all events for your operation, including events from all of the processes in your cluster when you are using distributed training. If you are running a distributed training job, your job-level logs are reported for the master worker process. The first step of troubleshooting an error is typically to examine the logs for that process, filtering out logged events for other processes in your cluster. The examples in this section show that filtering.
You can filter the logs from the command line or in the Cloud Logging section of your Google Cloud console. In either case, use these metadata values in your filter as needed:
| Metadata item | Filter to show items where it is... |
|---|---|
| resource.type | Equal to "cloud_ml_job". |
| resource.labels.job_id | Equal to your job name. |
| resource.labels.task_name | Equal to "master-replica-0" to read only the log entries for your master worker. |
| severity | Greater than or equal to ERROR to read only the log entries corresponding to error conditions. |
Command Line
Use gcloud beta logging read to construct a query that meets your needs. Here are some examples:
Each example relies on these environment variables:
PROJECT="my-project-name"
JOB="my_job_name"
You can enter the string literal in place instead if you prefer.
To print your job logs to screen:
gcloud ai-platform jobs stream-logs $JOB
See all the options for gcloud ai-platform jobs stream-logs.
To print the log for your master worker to screen:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
To print only errors logged for your master worker to screen:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
The preceding examples represent the most common cases of filtering for the logs from your AI Platform Prediction training job. Cloud Logging provides many powerful options for filtering that you can use if you need to refine your search. The advanced filtering documentation describes those options in detail.
Console
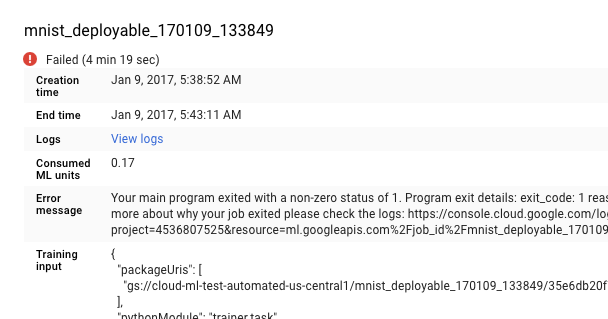
Open the AI Platform Prediction Jobs page in the Google Cloud console.
Select the job that failed from the list on the Jobs page to view its details.

- Click View logs to open Cloud Logging.
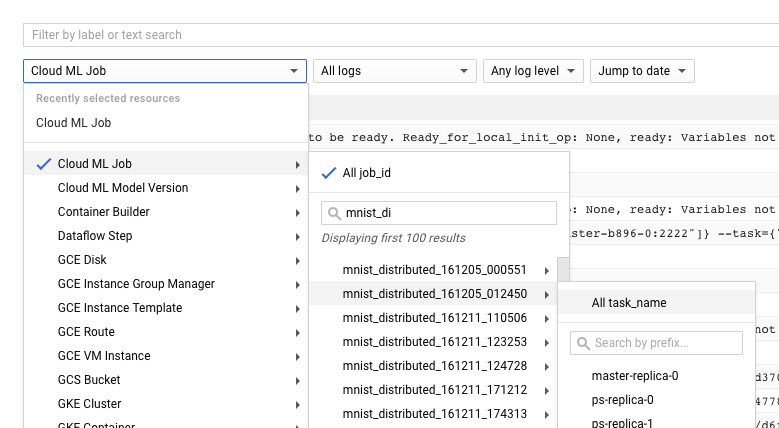
You can also go directly to Cloud Logging, but you have the added step of finding your job:
- Expand the resources selector.
- Expand AI Platform Prediction Job in the resources list.
- Find your job name in the job_id list (you can enter the first few letters of the job name in the search box to narrow the jobs displayed).
- Expand the job entry and select
master-replica-0from the task list.
Getting information from the logs
After you have found the right log for your job and filtered it to
master-replica-0, you can examine the logged events to find the source of the
problem. This involves standard Python debugging procedure, but these things
bear remembering:
- Events have multiple levels of severity. You can filter to see just events of a particular level, like errors, or errors and warnings.
- A problem that causes your trainer to exit with an unrecoverable error condition (return code > 0) is logged as an exception preceded by the stack trace:
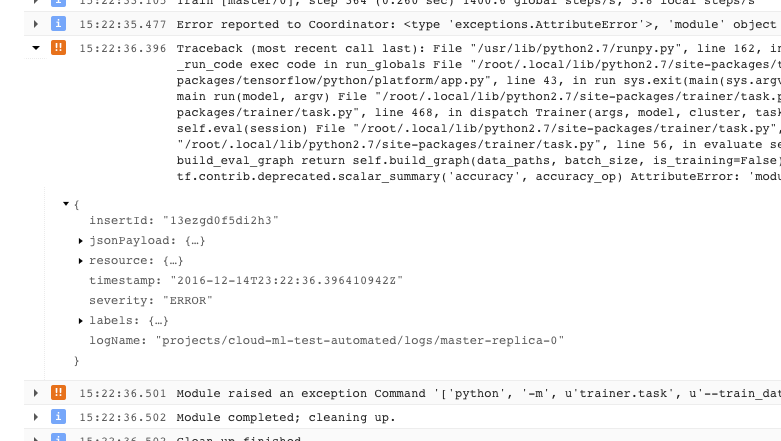
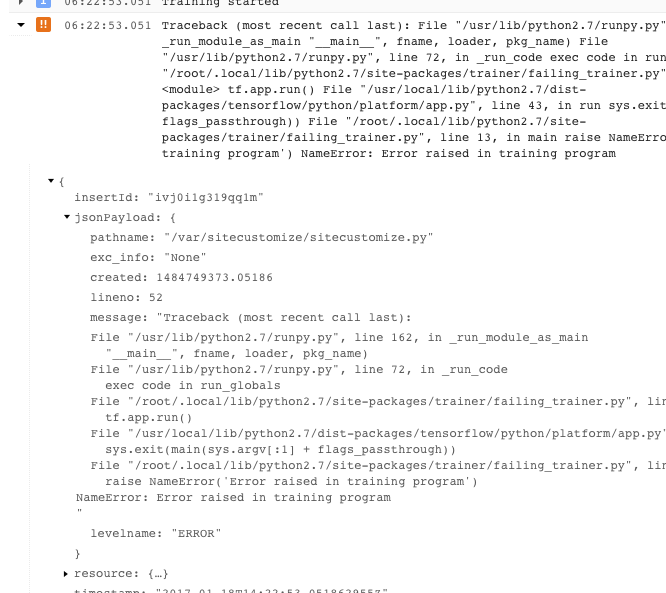
- You can get more information by expanding the objects in the logged JSON message (denoted by a right-facing arrow and contents listed as {...}). For example, you can expand jsonPayload to see the stack trace in a more readable form than is given in the main error description:
- Some errors show instances of retryable errors. These typically don't include a stack trace and can be more difficult to diagnose.
Getting the most out of logging
The AI Platform Prediction training service automatically logs these events:
- Status information internal to the service.
- Messages your trainer application sends to
stderr. - Output text your trainer application sends to
stdout.
You can make troubleshooting errors in your trainer application easier by following good programming practices:
- Send meaningful messages to stderr (with logging for example).
- Raise the most logical and descriptive exception when something goes wrong.
- Add descriptive strings to your exception objects.
The Python documentation provides more information about exceptions.
Troubleshooting prediction
This section gathers some common issues encountered when getting predictions.
Handling specific conditions for online prediction
This section provides guidance about some online prediction error conditions that are known to affect some users.
Predictions taking too long to complete (30-180 seconds)
The most common cause of slow online prediction is scaling processing nodes up from zero. If your model has regular prediction requests made against it, the system keeps one or more nodes ready to serve predictions. If your model hasn't served any predictions in a long time, the service "scales down" to zero ready nodes. The next prediction request after such a scale-down will take much more time to return than usual because the service has to provision nodes to handle it.
HTTP status codes
When an error occurs with an online prediction request, you usually get an HTTP status code back from the service. These are some commonly encountered codes and their meaning in the context of online prediction:
- 429 - Out of Memory
The processing node ran out of memory while running your model. There is no way to increase the memory allocated to prediction nodes at this time. You can try these things to get your model to run:
- Reduce your model size by:
- Using less precise variables.
- Quantizing your continuous data.
- Reducing the size of other input features (using smaller vocab sizes, for example).
- Send the request again with a smaller batch of instances.
- Reduce your model size by:
- 429 - Too many pending requests
Your model is getting more requests than it can handle. If you are using auto-scaling, it is getting requests faster than the system can scale. Further, if the minimum nodes value is 0, this configuration can lead to a "cold start" scenario where 100% error rate will be observed until the first node is viable.
With auto-scaling, you can try to resend requests with exponential backoff. Resending requests with exponential backoff can give the system time to adjust.
By default, auto-scaling is triggered by CPU utilization exceeding 60% and is configurable.
- 429 - Quota
Your Google Cloud Platform project is limited to 10,000 requests every 100 seconds (about 100 per second). If you get this error in temporary spikes, you can often retry with exponential backoff to process all of your requests in time. If you consistently get this code, you can request a quota increase. See the quota page for more details.
- 503 - Our systems have detected unusual traffic from your computer network
The rate of requests your model has received from a single IP is so high that the system suspects a denial of service attack. Stop sending requests for a minute and then resume sending them at a lower rate.
- 500 - Could not load model
The system had trouble loading your model. Try these steps:
- Ensure that your trainer is exporting the right model.
- Try a test prediction with the
gcloud ai-platform local predictcommand. - Export your model again and retry.
Formatting errors for prediction requests
These messages all have to do with your prediction input.
- "Empty or malformed/invalid JSON in request body"
- The service couldn't parse the JSON in your request or your request is empty. Check your message for errors or omissions that invalidate JSON.
- "Missing 'instances' field in request body"
- Your request body doesn't follow the correct format. It should be a JSON
object with a single key named
"instances"that contains a list with all of your input instances. - JSON encoding error when creating a request
Your request includes base64 encoded data, but not in the proper JSON format. Each base64 encoded string must be represented by an object with a single key named
"b64". For example:{"b64": "an_encoded_string"}Another base64 error occurs when you have binary data that isn't base64 encoded. Encode your data and format it as follows:
{"b64": base64.b64encode(binary_data)}See more information on formatting and encoding binary data.
Prediction in the cloud takes longer than on the desktop
Online prediction is designed to be a scalable service that quickly serves a high rate of prediction requests. The service is optimized for aggregate performance across all of the serving requests. The emphasis on scalability leads to different performance characteristics than generating a small number of predictions on your local machine.
What's next
- Get support.
- Learn more about the Google APIs error model,
in particular the canonical error codes defined in
google.rpc.Codeand the standard error details defined in google/rpc/error_details.proto. - Learn how to monitor your training jobs.
- See the Cloud TPU troubleshooting and FAQ for help diagnosing and solving problems when running AI Platform Prediction with Cloud TPU.