This document describes the Google Distributed Cloud (GDC) air-gapped resource hierarchy and how resources are managed in an air-gapped instance. For concepts on managing resources across multiple zones, see the Multi-zone overview.
The purpose of the GDC resource hierarchy is twofold:
- Provide a hierarchy of ownership, which binds the lifecycle of a resource to its immediate parent in the hierarchy.
- Provide attach points and inheritance for access control and organization policies.
The GDC resource hierarchy resembles the file system found in operating systems as a way of organizing and managing entities hierarchically. Generally, each resource has exactly one parent. This hierarchical organization of resources lets you set access control policies, such as Identity and Access Management (IAM), which are inherited by child resources.
For more information on best practices for organizing your access boundaries, see Design access boundaries between resources.
Resource structure in detail
The following entities are resource types recognized in the GDC resource hierarchy:
GDC resources are organized hierarchically. Most resources in the resource hierarchy have exactly one parent. The exception only applies to the highest resource. At the lowest level, service resources are the fundamental components that make up all GDC services.
An organization is the top of the GDC resource hierarchy, and all resources that belong to an organization are grouped under the organization resource. This provides central visibility and control over every resource that belongs to an organization.
Both projects and clusters are organization-scoped. They can be attached to one another to organize service resources. However, projects and clusters function independently from one another. This flexibility provides many different options for how to organize services and workloads. For example, you can have a cluster dedicated to a single project. Likewise, a cluster can span across multiple projects.
Service resources are entities that must belong to a project or a cluster, and cannot be shared across projects or clusters. Examples of service resources include virtual machines (VMs), databases, storage buckets, and backups. Most of these lower-level resources have project resources as their parents.
The following diagram represents an example GDC resource hierarchy:
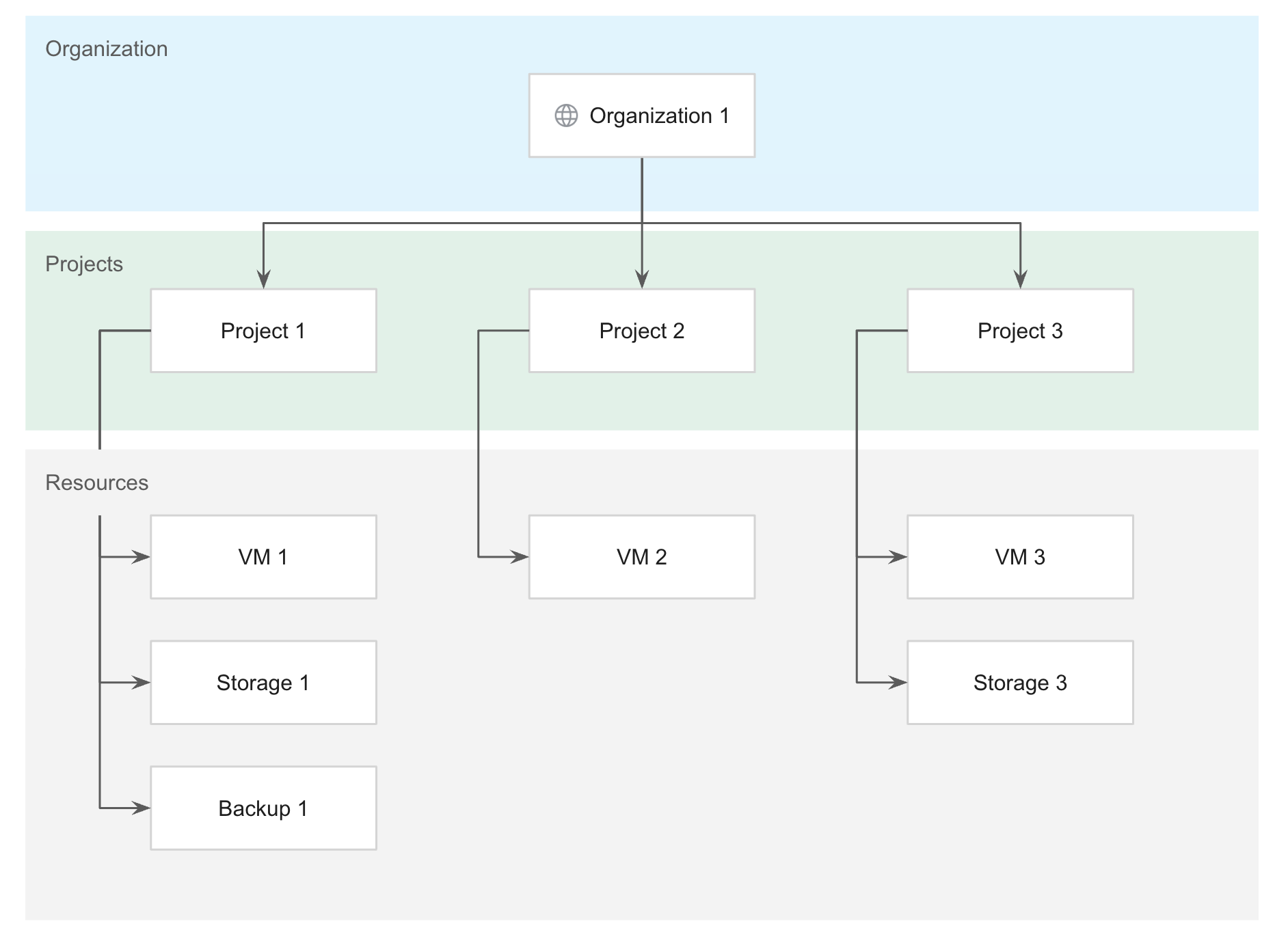
For more information on best practices for organizing your resource hierarchy for optimal workload management, see Design user workload separation.
Organization
The organization resource represents an administrative unit or a business function, such as a company, and is the top-level resource in the GDC resource hierarchy. An organization defines a security boundary that encloses infrastructure resources to be administered together so that users can deploy application workloads. Organizations are global and span all zones in a universe. Within an organization, service resources such as VMs and storage volumes are logically grouped by projects.
All projects, clusters, and service resources belong to your organization instead of their creators. This means that any resource type for an organization is not deleted if the user who created it leaves the organization. Instead, all resource types follow the organization's lifecycle in GDC.
The IAM access control policies applied to the organization resource apply throughout the hierarchy on all resources in the organization. For more information on granting organization-wide policies and permissions, see the Organization policies and IAM sections.
Project
A project is a tenancy unit that every service must integrate. Projects provide logical grouping of service resources. Projects are global and span all zones in a universe.
Projects enable segmentation of service resources within an organization and provide a lifecycle and policy boundary for managing resources. Service resources inside a project can never outlive the project itself or move between projects, ensuring that control is available for the life of a resource. Therefore, you must deploy resources of any type within a project namespace.
A project is considered a proper Kubernetes namespace that spans across multiple clusters in an organization. Namespace sameness considers all namespaces of a given name the same namespace for all clusters within the same organization. The single namespace has a consistent owner across the set of clusters. Service providers create project-scoped services by creating control plane and data plane components in the namespace.
The namespace for a project hosts the following:
- Project-scoped service APIs.
- Project-level policy configurations, such as roles and role bindings.
You can attach a project to only a subset of clusters in an organization. You can deploy containerized workloads on these clusters within a project namespace. The namespace sameness concept applies to the project namespace on these clusters. Namespace-scoped policies, such as role-based access (RBAC) policies, apply to all those namespaces.
For more information on projects, see the Projects overview.
Kubernetes cluster
A Kubernetes cluster is a set of nodes that run containerized workloads as part of GKE on GDC. You can provision Kubernetes clusters to support the compute requirements of your applications. Clusters are organization-scoped, and must be attached to one or more projects.
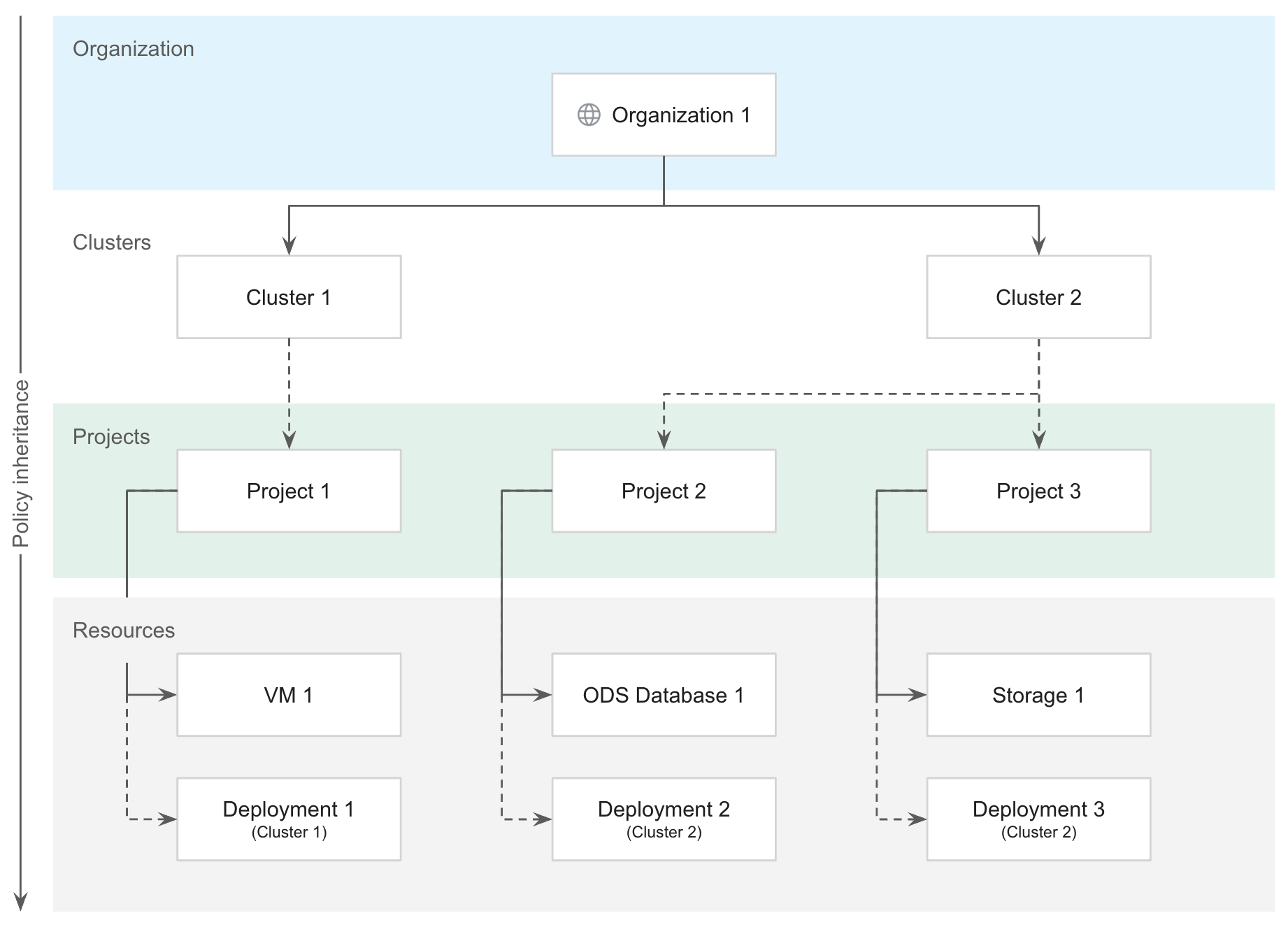
Clusters subdivide infrastructure resources into isolated pools to be consumed by projects within an organization. Clusters are also logically separated from each other to provide different failure domains and isolation guarantees. The enforcement of policies per organization ensures clusters can be shared across teams and users while also maintaining performance and resource guarantees. Additionally, organization policies enables VM workloads to run alongside container workloads without introducing operational complexity.
Clusters are beneficial for instances where you must deploy containerized workloads. However, with the option to deploy VM-based workloads, the existence of a Kubernetes cluster is not required in GDC.
Clusters are a zonal resource only and cannot span multiple zones. To operate clusters in a multi-zone deployment, you must manually deploy clusters in each zone.
For more information on Kubernetes clusters, see the Manage Kubernetes clusters section.
Service resource
Service resources include many entities, such as:
- VMs
- Databases
- Storage buckets
- Containerized workloads
- Backups
Service resources must belong to a project, or optionally a cluster for containerized workloads, and they cannot be shared across projects. This means that service resources inside a project can never outlive the project itself, ensuring that control is available for the life of the resource.
Service resources can be deployed globally or zonally depending on the type. Reference the specific service's documentation for information on multi-zone deployment options. Service resources are enabled by default and can be disabled using an organization policy.