Vous consultez la documentation d'Apigee et d'Apigee hybrid.
Consultez la documentation d'Apigee Edge.
Symptômes
Les déploiements de proxys d'API échouent avec l'avertissement Aucun pod d'exécution actif dans l'interface utilisateur Apigee hybrid.
Messages d'erreur
L'avertissement No active runtime pods (Aucun pod d'exécution actif) s'affiche dans la boîte de dialogue Details (Détails) à côté du message d'erreur Deployment issues on ENVIRONMENT: REVISION_NUMBER (Problèmes de déploiement sur test1 : révision 2) sur la page du proxy d'API :

Ce problème peut se manifester par des erreurs différentes dans d'autres pages de ressources de l'interface utilisateur. Voici quelques exemples de messages d'erreur :
Message d'erreur de l'interface utilisateur hybride #1 : erreur Datastore
Vous pouvez observer la Datastore Error (erreur Datastore) sur les pages API Products (Produits d'API) et Apps (Applications) de l'interface utilisateur hybride, comme indiqué ci-dessous :

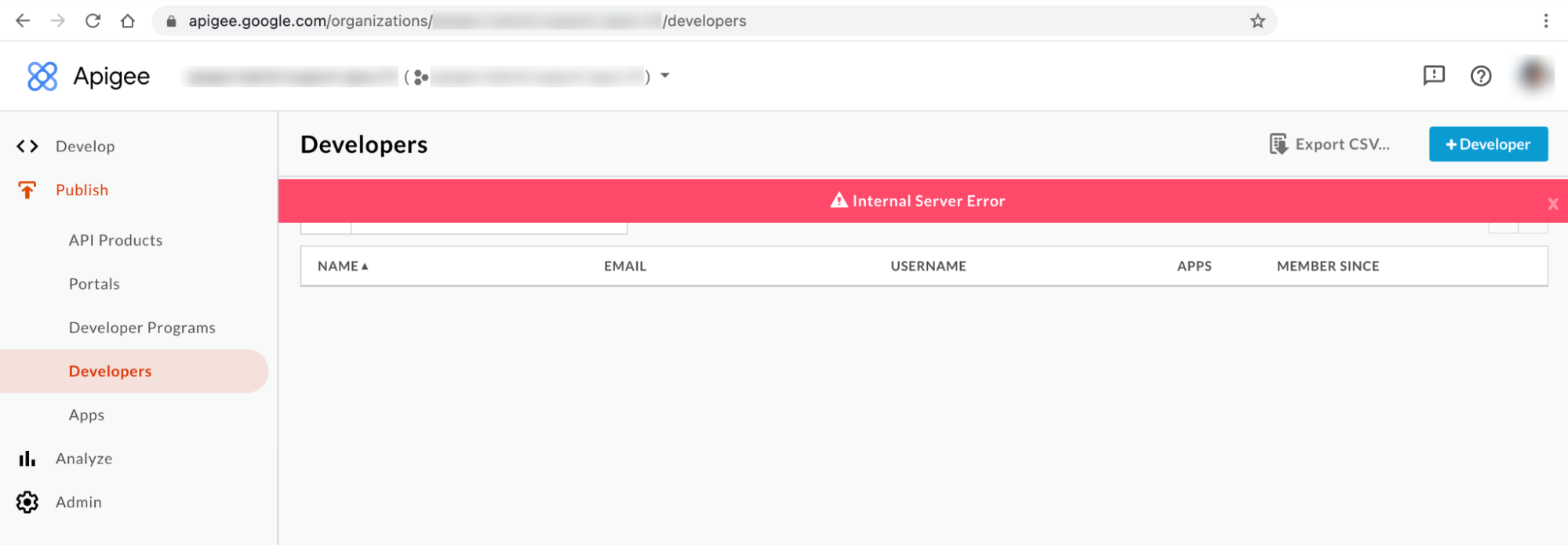
Message d'erreur de l'interface utilisateur hybride #2 : erreur interne du serveur
Vous pouvez constater une Internal Server Error (Erreur interne du serveur) sur la page Developers (Développeurs) de l'interface utilisateur, comme indiqué ci-dessous :
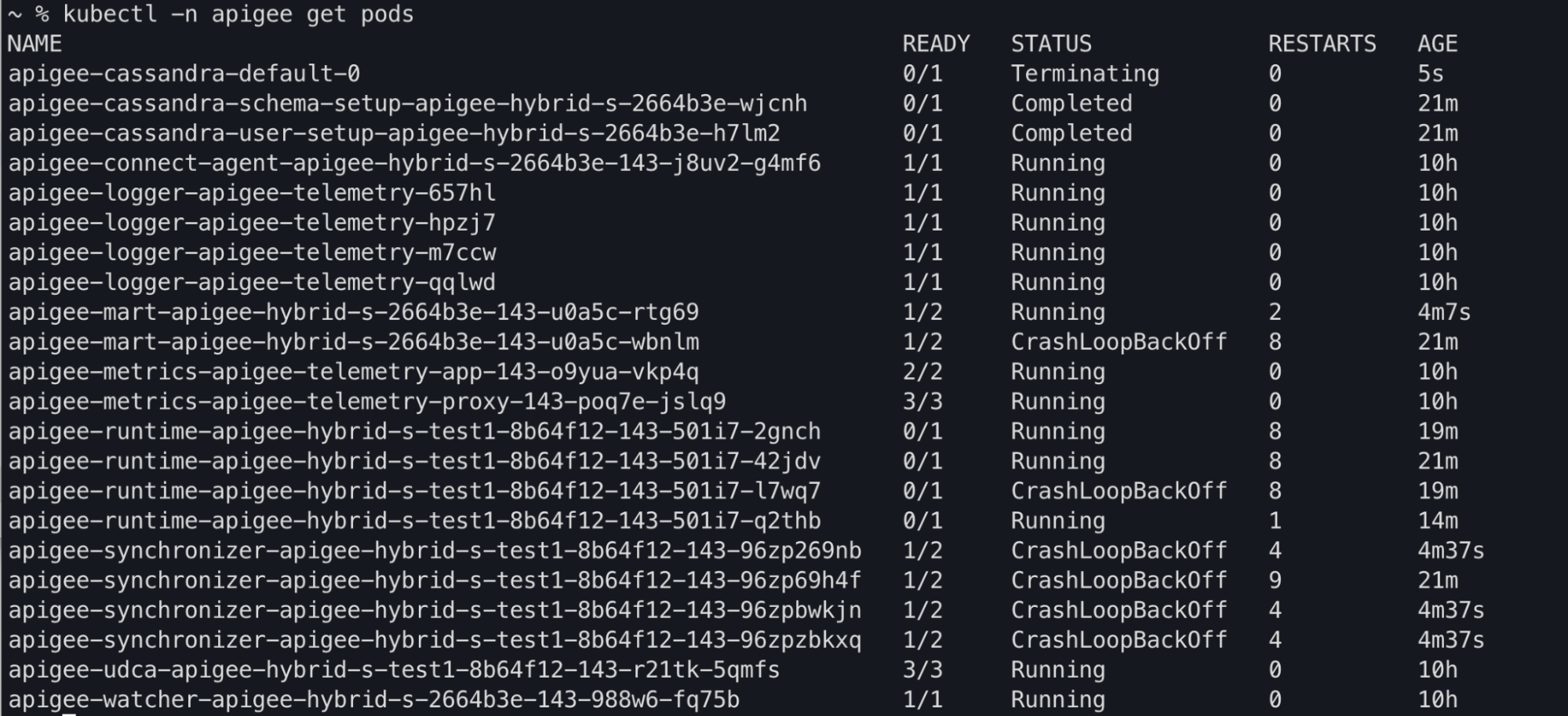
Résultat de la commande kubectl
Vous pouvez observer que les états des pods apiege-mart, apigee-runtime et apigee-
synchronizer sont remplacés par CrashLoopBackOff dans le résultat de la commande kubectl get pods :
Messages d'erreur du journal des composants
Vous allez observer les erreurs liées à la défaillance de la vérification d'activité suivantes dans les journaux des pods apigee-runtime issus des versions d'Apigee hybrid >= 1.4.0 :
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.GeneratedMethodAccessor52.invoke(Unknown
Source)\n\tsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\t
","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
Vous remarquerez l'erreur Cannot build a cluster without contact points suivante dans les journaux des pods apigee-synchronizer issus des versions Apigee hybrid >= 1.4.0 :
{"timestamp":"1621575636434","level":"ERROR","thread":"main","logger":"KERNEL.DEPLOYMENT","message":
"ServiceDeployer.deploy() : Got a life cycle exception while starting service [SyncService, Cannot
build a cluster without contact points] : {}","context":"apigee-service-
logs","exception":"java.lang.IllegalArgumentException: Cannot build a cluster without contact
points\n\tat com.datastax.driver.core.Cluster.checkNotEmpty(Cluster.java:134)\n\tat
com.datastax.driver.core.Cluster.<init>(Cluster.java:127)\n\tat
com.datastax.driver.core.Cluster.buildFrom(Cluster.java:193)\n\tat
com.datastax.driver.core.Cluster$Builder.build(Cluster.java:1350)\n\tat
io.apigee.persistence.PersistenceContext.newCluster(PersistenceContext.java:214)\n\tat
io.apigee.persistence.PersistenceContext.<init>(PersistenceContext.java:48)\n\tat
io.apigee.persistence.ApplicationContext.<init>(ApplicationContext.java:19)\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceImpl.<init>(RuntimeConfigServiceImpl.java:75)
\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceFactory.newInstance(RuntimeConfigServiceFactory.
java:99)\n\tat
io.apigee.common.service.AbstractServiceFactory.initializeService(AbstractServiceFactory.java:301)\n
\tat
...","severity":"ERROR","class":"com.apigee.kernel.service.deployment.ServiceDeployer","method":"sta
rtService"}
Vous allez observer les erreurs liées à la défaillance de la vérification d'activité suivantes dans les journaux des pods apigee-mart issus des versions d'Apigee hybrid >= 1.4.0 :
{"timestamp":"1621576757592","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.NativeMethodAccessorImpl.invoke0(Native
Method)\n\tsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\t","conte
xt":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621576757593","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}Informations sur l'erreur "Aucun pod d'exécution actif"
Dans la version 1.4.0 d'Apigee hybrid, la fonctionnalité de vérification d'activité a été ajoutée aux pods apigee-runtime et apigee-mart pour vérifier l'état des pods Cassandra. Si tous les pods Cassandra deviennent indisponibles, les vérifications d'activité des pods apigee-runtime et apigee-mart échouent. Ainsi, les pods apigee-runtime et apigee-mart passent à l'état CrashLoopBackOff , ce qui entraîne l'échec des déploiements de proxys d'API avec l'avertissement No active runtime pods.
Le pod apigee-synchronizer passe également à l'état CrashLoopBackOff , car les pods Cassandra sont indisponibles.
Causes possibles
Voici quelques causes possibles de cette erreur :
| Cause | Description |
|---|---|
| Les pods Cassandra sont indisponibles | Les pods Cassandra sont indisponibles. Par conséquent, les pods apigee-runtime ne pourront pas communiquer avec la base de données Cassandra. |
| Instance dupliquée Cassandra configurée avec un seul pod | Le fait de disposer d'un seul pod Cassandra peut devenir un point de défaillance unique. |
Cause : les pods Cassandra sont indisponibles
Au cours du processus de déploiement du proxy d'API, les pods apigee-runtime se connectent à la base de données Cassandra pour récupérer les ressources, telles que les mappages clé-valeur et les caches, définis dans le proxy d'API. Si aucun pod Cassandra n'est en cours d'exécution, les pods apigee-runtime ne pourront pas se connecter à la base de données Cassandra. Cela entraîne l'échec du déploiement du proxy d'API.
Diagnostic
- Répertoriez les pods Cassandra :
kubectl -n apigee get pods -l app=apigee-cassandra
Exemple de résultat 1 :
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 0/1 Pending 0 9m23s
Exemple de résultat 2 :
NAME READY STATUS RESTARTS AGE apigee-cassandra-0 0/1 CrashLoopBackoff 0 10m
- Vérifiez l'état de chaque pod Cassandra. L'état de tous les pods Cassandra doit être à l'état
Running. Si l'un des pods Cassandra est dans un état différent, il peut s'agir du problème. Pour résoudre le problème, procédez comme suit :
Solution
- Si l'un des pods Cassandra affiche l'état
Pending, consultez la section Les pods Cassandra sont bloqués dans l'état "En attente" pour résoudre le problème. - Si l'un des pods Cassandra affiche l'état
CrashLoopBackoff, reportez-vous à la section Les pods Cassandra sont bloqués dans l'état CrashLoopBackoff pour résoudre le problème.Exemple de résultat :
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Cause : instance dupliquée Cassandra configurée avec un seul pod
Si le nombre d'instances dupliquées Cassandra est configuré sur un, un seul pod Cassandra est disponible dans l'environnement d'exécution. Par conséquent, les pods apigee-runtime peuvent rencontrer des problèmes de connectivité si ce pod Cassandra devient indisponible pendant une période donnée.
Diagnostic
- Obtenez l'ensemble avec état Cassandra et vérifiez le nombre d'instances dupliquées actuel :
kubectl -n apigee get statefulsets -l app=apigee-cassandra
Exemple de résultat :
NAME READY AGE apigee-cassandra-default 1/1 21m
- Si le nombre d'instances dupliquées est défini sur un, procédez comme suit pour l'augmenter.
Solution
Le nombre d'instances dupliquées Cassandra peut être défini sur un pour les déploiements Apigee hybrid hors production. Si la haute disponibilité de Cassandra est importante dans les déploiements hors production, augmentez le nombre d'instances dupliquées à trois pour résoudre ce problème.
Pour résoudre ce problème, procédez comme suit :
- Mettez à jour le fichier
overrides.yamlet définissez le nombre d'instances dupliquées Cassandra sur trois :cassandra: replicaCount: 3
Pour en savoir plus sur la configuration Cassandra, consultez la documentation de référence sur les propriétés de configuration.
- Appliquez la configuration ci-dessus à l'aide de la CLI
apigeectl:cd path/to/hybrid-files apigeectl apply -f overrides/overrides.yaml
- Obtenez l'ensemble avec état Cassandra et vérifiez le nombre d'instances dupliquées actuel :
kubectl -n get statefulsets -l app=apigee-cassandra
Exemple de résultat :
NAME READY AGE apigee-cassandra-default 3/3 27m
- Obtenez les pods Cassandra et vérifiez le nombre d'instances actuel. Si tous les pods ne sont pas prêts et sont à l'état
Running, attendez que les nouveaux pods Cassandra soient créés et activés :kubectl -n get pods -l app=apigee-cassandra
Exemple de résultat :
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 1/1 Running 0 29m apigee-cassandra-default-1 1/1 Running 0 21m apigee-cassandra-default-2 1/1 Running 0 19m
Exemple de résultat :
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Vous devez collecter des informations de diagnostic
Si le problème persiste, même après avoir suivi les instructions ci-dessus, rassemblez les informations de diagnostic suivantes, puis contactez Google Cloud Customer Care :
- ID de projet Google Cloud
- Organisation Apigee hybrid/Apigee
- Pour Apigee hybrid : le fichier
overrides.yaml, masque les informations sensibles - État du pod Kubernetes dans tous les espaces de noms :
kubectl get pods -A > kubectl-pod-status`date +%Y.%m.%d_%H.%M.%S`.txt
- Fichier de vidage cluster-info Kubernetes :
# generate kubernetes cluster-info dump kubectl cluster-info dump -A --output-directory=/tmp/kubectl-cluster-info-dump # zip kubernetes cluster-info dump zip -r kubectl-cluster-info-dump`date +%Y.%m.%d_%H.%M.%S`.zip /tmp/kubectl-cluster-info-dump/*
Références
- Scaling horizontal de Cassandra
- Présentation et débogage de l'application Kubernetes
- Aide-mémoire sur kubectl.