Estás consultando la documentación de Apigee y Apigee Hybrid.
Consulta la documentación de
Apigee Edge.
Síntomas
Los despliegues de proxies de APIs fallan y se muestra la advertencia No active runtime pods (No hay pods de entorno de ejecución activos) en la interfaz de usuario híbrida de Apigee.
Mensajes de error
La advertencia No active runtime pods (No hay pods de entorno de ejecución activos) se muestra en el cuadro de diálogo Details (Detalles) junto al mensaje de error Deployment issues on ENVIRONMENT: REVISION_NUMBER (Problemas de implementación en ENVIRONMENT: REVISION_NUMBER) en la página del proxy de API:
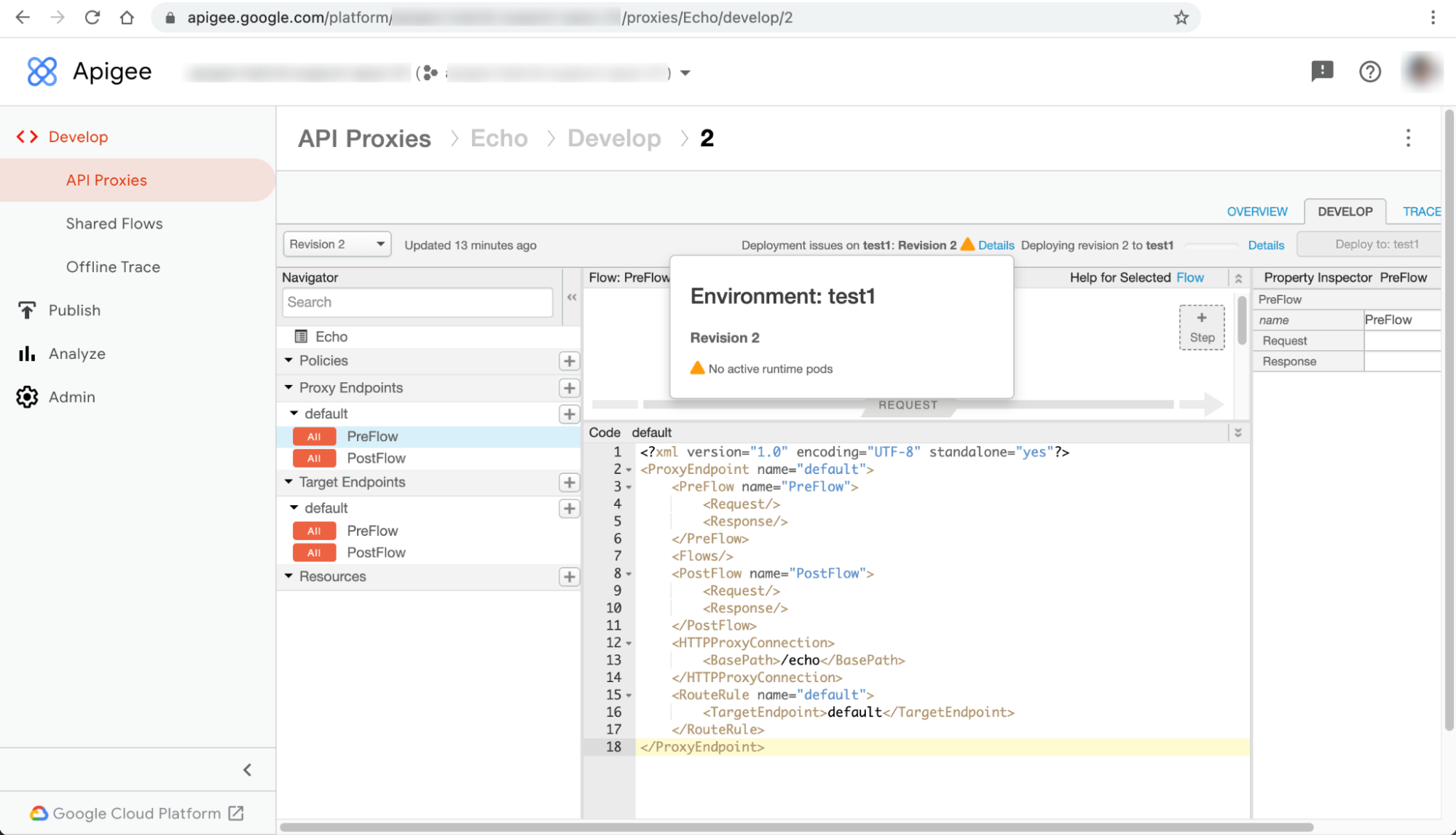
Este problema puede manifestarse como diferentes errores en otras páginas de recursos de la interfaz de usuario. Estos son algunos ejemplos de mensajes de error:
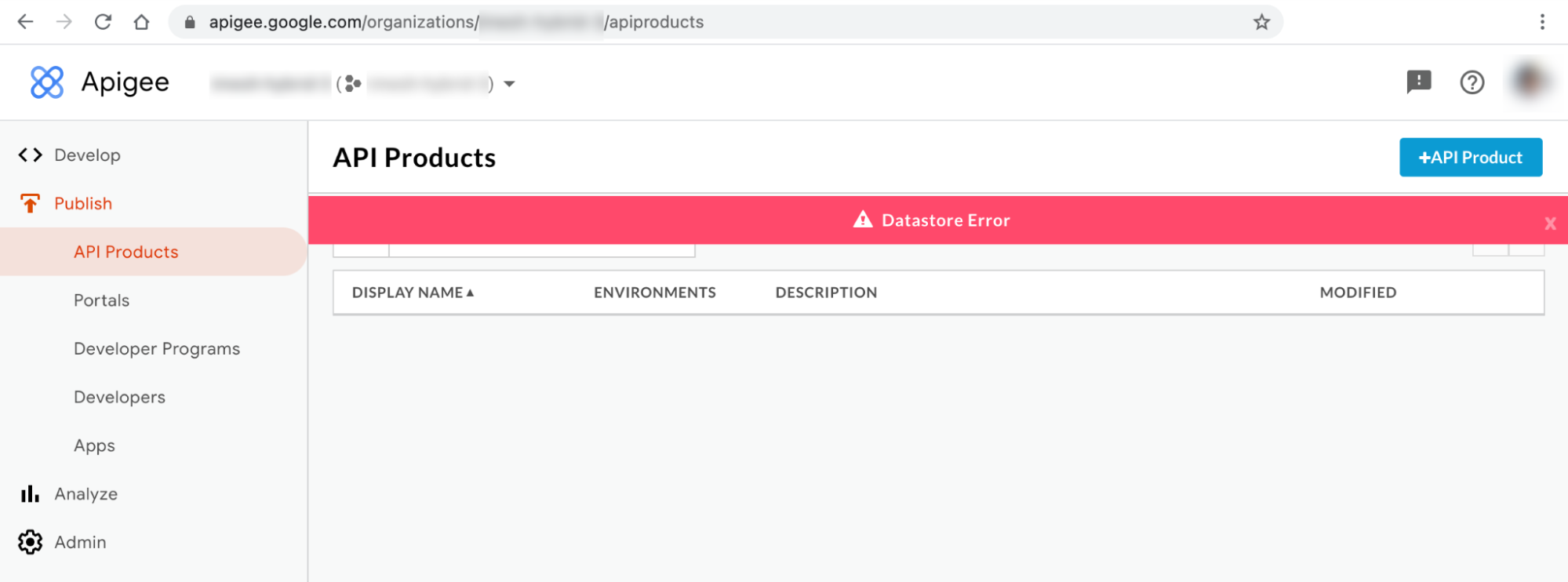
Mensaje de error de interfaz de usuario híbrida 1: Error de almacén de datos
Puede observar el error de Datastore en las páginas Productos de API y Aplicaciones de la interfaz de usuario híbrida, como se muestra a continuación:
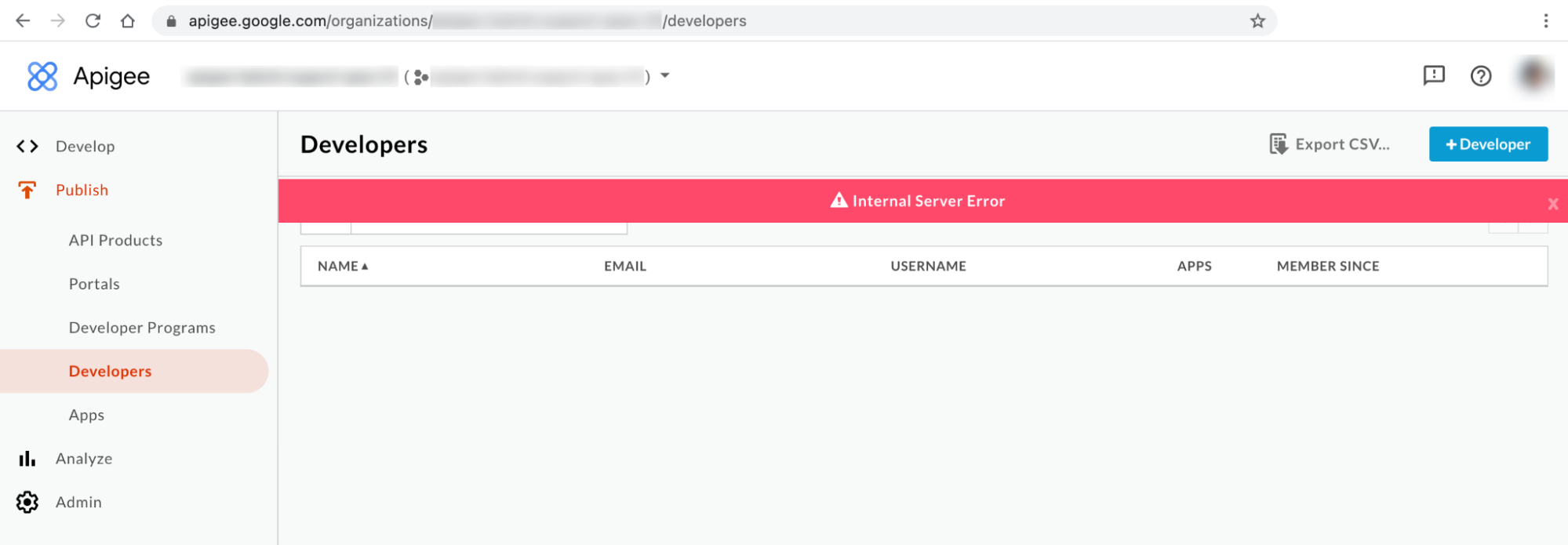
Mensaje de error de interfaz de usuario híbrida 2: error de servidor interno
Puede que vea el mensaje Error de servidor interno en la página Desarrolladores de la interfaz de usuario, como se muestra a continuación:
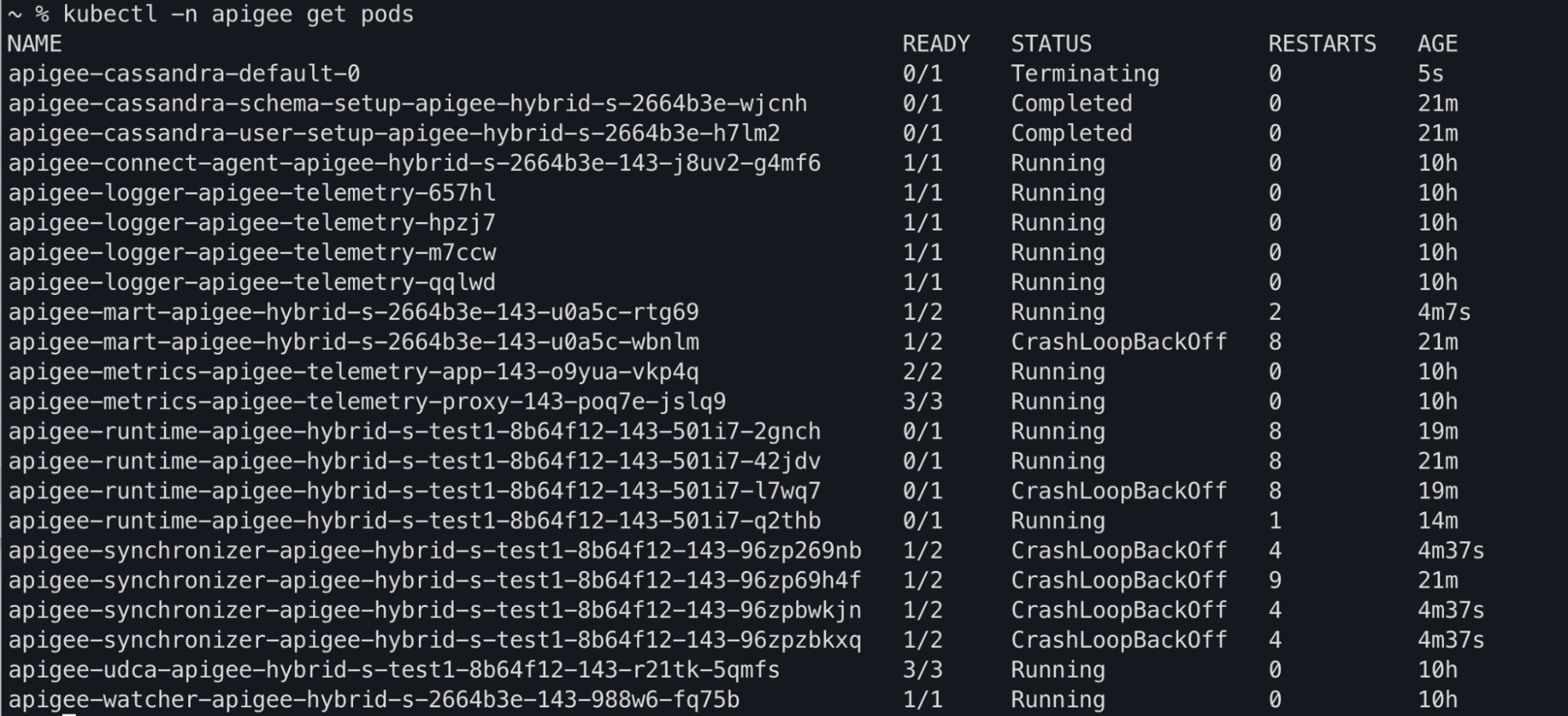
Resultado del comando Kubectl
Puede observar que los estados de los pods apiege-mart, apigee-runtime y apigee-
synchronizer cambian a CrashLoopBackOff en la salida del comando kubectl get pods:
Mensajes de error de los registros de componentes
Verás los siguientes errores de fallo de la prueba de actividad en los registros de pods de las versiones de Apigee hybrid >= 1.4.0:apigee-runtime
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.GeneratedMethodAccessor52.invoke(Unknown
Source)\n\tsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\t
","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
Verás el siguiente Cannot build a cluster without contact points error
en los registros de pods de apigee-synchronizer en las versiones de Apigee hybrid >= 1.4.0:
{"timestamp":"1621575636434","level":"ERROR","thread":"main","logger":"KERNEL.DEPLOYMENT","message":
"ServiceDeployer.deploy() : Got a life cycle exception while starting service [SyncService, Cannot
build a cluster without contact points] : {}","context":"apigee-service-
logs","exception":"java.lang.IllegalArgumentException: Cannot build a cluster without contact
points\n\tat com.datastax.driver.core.Cluster.checkNotEmpty(Cluster.java:134)\n\tat
com.datastax.driver.core.Cluster.<init>(Cluster.java:127)\n\tat
com.datastax.driver.core.Cluster.buildFrom(Cluster.java:193)\n\tat
com.datastax.driver.core.Cluster$Builder.build(Cluster.java:1350)\n\tat
io.apigee.persistence.PersistenceContext.newCluster(PersistenceContext.java:214)\n\tat
io.apigee.persistence.PersistenceContext.<init>(PersistenceContext.java:48)\n\tat
io.apigee.persistence.ApplicationContext.<init>(ApplicationContext.java:19)\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceImpl.<init>(RuntimeConfigServiceImpl.java:75)
\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceFactory.newInstance(RuntimeConfigServiceFactory.
java:99)\n\tat
io.apigee.common.service.AbstractServiceFactory.initializeService(AbstractServiceFactory.java:301)\n
\tat
...","severity":"ERROR","class":"com.apigee.kernel.service.deployment.ServiceDeployer","method":"sta
rtService"}
En las versiones de Apigee hybrid >= 1.4.0, verás los siguientes errores de fallo de la sonda de actividad en los registros del pod apigee-mart:
{"timestamp":"1621576757592","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.NativeMethodAccessorImpl.invoke0(Native
Method)\n\tsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\t","conte
xt":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621576757593","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}Información sobre el error No active runtime pods
En la versión 1.4.0 de Apigee Hybrid, se añadió la función de comprobación de actividad a los pods apigee-runtime y apigee-mart para comprobar el estado de los pods de Cassandra. Si todos los pods de Cassandra dejan de estar disponibles, las comprobaciones de actividad de los pods apigee-runtime y apigee-mart fallarán. Por lo tanto, los pods apigee-runtime y apigee-mart pasarán al estado CrashLoopBackOff , lo que provocará que los despliegues de proxies de APIs fallen y se muestre la advertencia No active runtime pods.
El pod apigee-synchronizer también pasará al estado CrashLoopBackOff
porque los pods de Cassandra no están disponibles.
Posibles motivos
A continuación se indican algunas de las posibles causas de este error:
| Causa | Descripción |
|---|---|
| Los pods de Cassandra no funcionan | Los pods de Cassandra no funcionan, por lo que los pods de apigee-runtime no podrán comunicarse con la base de datos de Cassandra. |
| Réplica de Cassandra configurada con un solo pod | Si solo tienes un pod de Cassandra, podría convertirse en un punto único de fallo. |
Causa: los pods de Cassandra no funcionan
Durante el proceso de implementación del proxy de API, los pods apigee-runtime se conectan a la base de datos de Cassandra para obtener recursos, como mapas de valores de clave (KVMs) y cachés, definidos en el proxy de API. Si no hay pods de Cassandra en ejecución, los pods de apigee-runtime no podrán conectarse a la base de datos de Cassandra. Esto provoca un error en la implementación del proxy de API.
Diagnóstico
- Lista de pods de Cassandra:
kubectl -n apigee get pods -l app=apigee-cassandra
Ejemplo de salida 1:
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 0/1 Pending 0 9m23s
Ejemplo de salida 2:
NAME READY STATUS RESTARTS AGE apigee-cassandra-0 0/1 CrashLoopBackoff 0 10m
- Verifica el estado de cada pod de Cassandra. El estado de todos los pods de Cassandra debe ser
Running. Si alguno de los pods de Cassandra tiene un estado diferente, ese podría ser el motivo del problema. Sigue estos pasos para solucionar el problema:
Resolución
- Si alguno de los pods de Cassandra está en el estado
Pending, consulta el artículo Los pods de Cassandra se quedan en el estado Pendiente para solucionar el problema. - Si alguno de los pods de Cassandra está en estado
CrashLoopBackoff, consulta el artículo Los pods de Cassandra se quedan atascados en el estado CrashLoopBackoff para solucionar el problema.Ejemplo de salida:
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Causa: réplica de Cassandra configurada con un solo pod
Si el número de réplicas de Cassandra es uno, solo habrá un pod de Cassandra disponible en el tiempo de ejecución. Por lo tanto, es posible que los pods de apigee-runtime tengan problemas de conectividad si el pod de Cassandra no está disponible durante un periodo determinado.
Diagnóstico
- Obtén el conjunto con estado de Cassandra y comprueba el número de réplicas actual:
kubectl -n apigee get statefulsets -l app=apigee-cassandra
Ejemplo de salida:
NAME READY AGE apigee-cassandra-default 1/1 21m
- Si el número de réplicas es 1, sigue estos pasos para aumentarlo.
Resolución
Las implementaciones de Apigee hybrid que no son de producción pueden tener el número de réplicas de Cassandra definido en 1. Si la alta disponibilidad de Cassandra es importante en las implementaciones que no son de producción, aumenta el número de réplicas a 3 para resolver este problema.
Sigue estos pasos para solucionar el problema:
- Actualiza el archivo
overrides.yamly define el número de réplicas de Cassandra en 3:cassandra: replicaCount: 3
Para obtener información sobre la configuración de Cassandra, consulta la referencia de la propiedad de configuración.
- Aplica la configuración anterior con Helm:
Prueba de funcionamiento:
helm upgrade datastore apigee-datastore/ \ --install \ --namespace APIGEE_NAMESPACE \ --atomic \ -f OVERRIDES_FILE \ --dry-run
Instala el gráfico de Helm
helm upgrade datastore apigee-datastore/ \ --install \ --namespace APIGEE_NAMESPACE \ --atomic \ -f OVERRIDES_FILE
- Obtén el conjunto con estado de Cassandra y comprueba el número de réplicas actual:
kubectl -n get statefulsets -l app=apigee-cassandra
Ejemplo de salida:
NAME READY AGE apigee-cassandra-default 3/3 27m
- Obtén los pods de Cassandra y comprueba el número de instancias actual. Si no todos los pods están listos y se encuentran en el estado
Running, espera a que se creen y se activen los nuevos pods de Cassandra:kubectl -n get pods -l app=apigee-cassandra
Ejemplo de salida:
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 1/1 Running 0 29m apigee-cassandra-default-1 1/1 Running 0 21m apigee-cassandra-default-2 1/1 Running 0 19m
Ejemplo de salida:
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Debe recoger información de diagnóstico
Si el problema persiste incluso después de seguir las instrucciones anteriores, recoge la siguiente información de diagnóstico y ponte en contacto con el equipo de Asistencia de Google Cloud.
- ID de proyecto de Google Cloud
- Organización de Apigee Hybrid o Apigee
- En Apigee Hybrid,
overrides.yaml, que oculta cualquier información sensible - Estado de los pods de Kubernetes en todos los espacios de nombres:
kubectl get pods -A > kubectl-pod-status`date +%Y.%m.%d_%H.%M.%S`.txt
- Volcado de información del clúster de Kubernetes:
# generate kubernetes cluster-info dump kubectl cluster-info dump -A --output-directory=/tmp/kubectl-cluster-info-dump # zip kubernetes cluster-info dump zip -r kubectl-cluster-info-dump`date +%Y.%m.%d_%H.%M.%S`.zip /tmp/kubectl-cluster-info-dump/*
Referencias
- Escalar Cassandra horizontalmente
- Introspección y depuración de aplicaciones de Kubernetes
- Hoja de referencia de kubectl