Stai visualizzando la documentazione di Apigee e Apigee hybrid.
Visualizza la documentazione di
Apigee Edge.
Sintomi
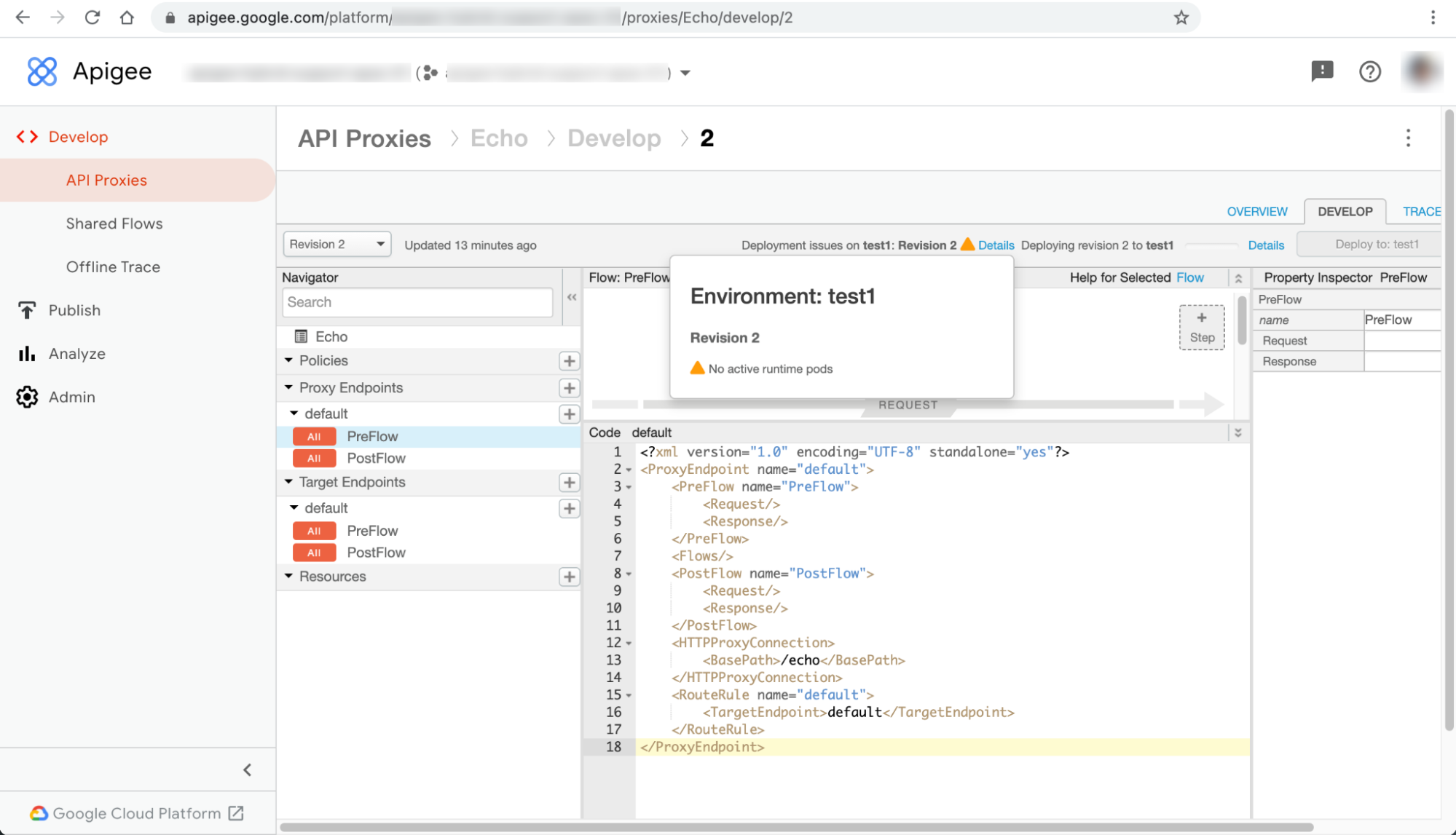
I deployment dei proxy API non riescono con l'avviso Nessun pod di runtime attivo nell'UI ibrida di Apigee.
Messaggi di errore
L'avviso Nessun pod di runtime attivo viene visualizzato nella finestra di dialogo Dettagli accanto al messaggio di errore Problemi di deployment su ENVIRONMENT:REVISION_NUMBER nella pagina del proxy API:
Questo problema può manifestarsi sotto forma di errori diversi in altre pagine delle risorse dell'interfaccia utente. Ecco alcuni esempi di messaggi di errore:
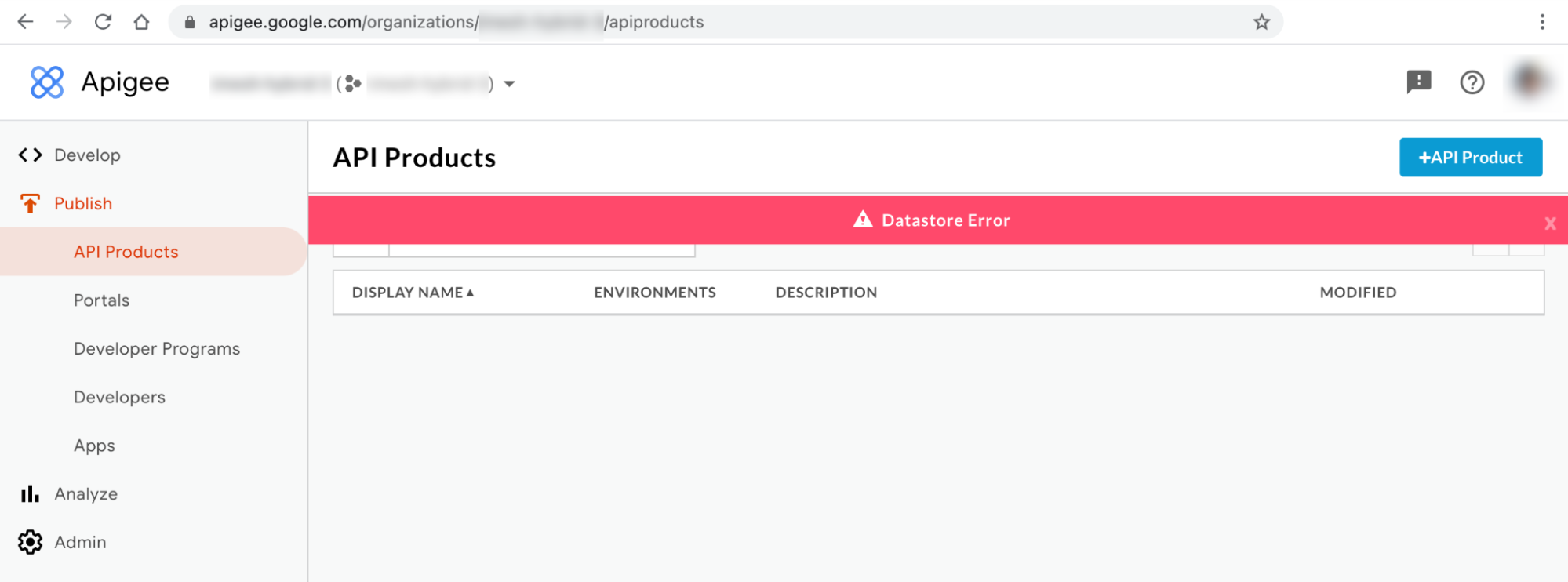
Messaggio di errore dell'interfaccia utente ibrida 1: errore del datastore
Potresti notare l'errore del datastore nelle pagine API Products e Apps dell'interfaccia utente ibrida, come mostrato di seguito:
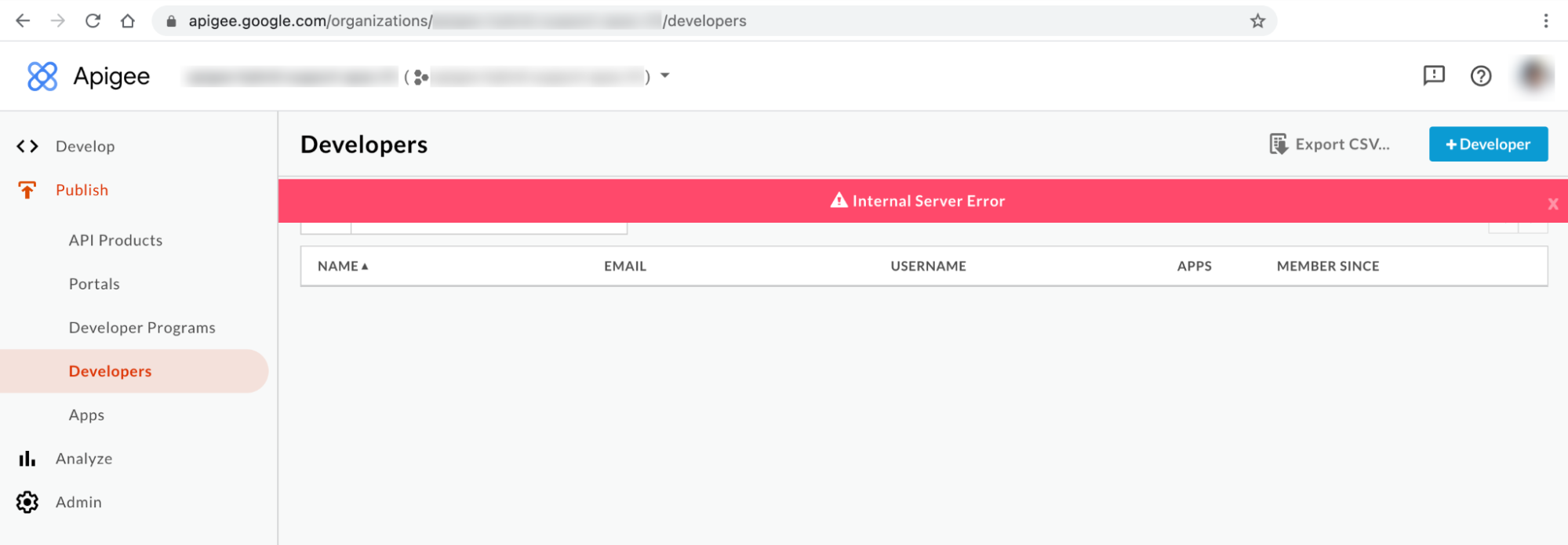
Messaggio di errore dell'interfaccia utente ibrida 2: Errore interno del server
Potresti visualizzare l'errore Internal Server Error (Errore interno del server) nella pagina Sviluppatori dell'interfaccia utente, come mostrato di seguito:
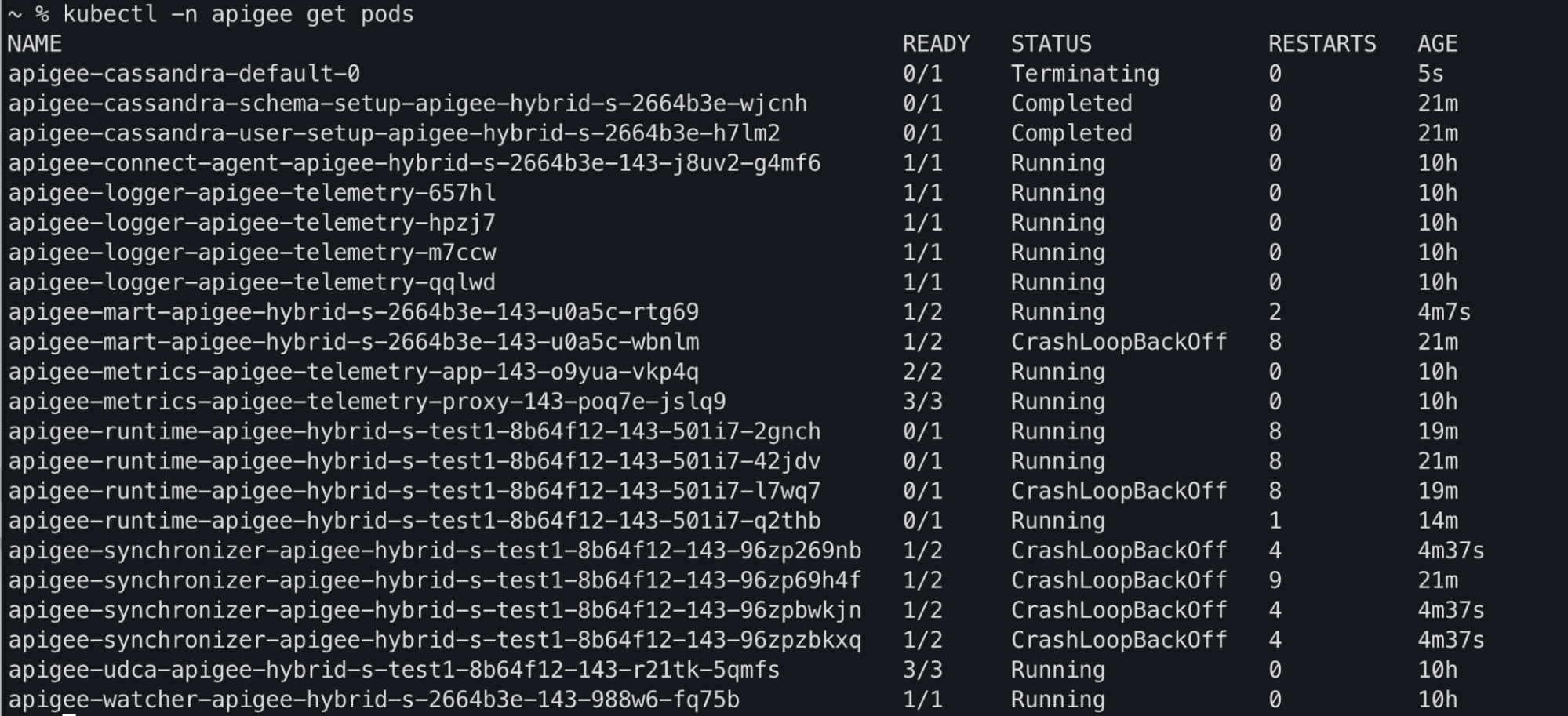
Output comando Kubectl
Potresti notare che gli stati dei pod apiege-mart, apigee-runtime e apigee-
synchronizer vengono modificati in CrashLoopBackOff nell'output comando kubectl get pods:
Messaggi di errore del log del componente
Nei log del pod apigee-runtime
nelle release ibride di Apigee >= 1.4.0 vedrai i seguenti errori di mancata risposta del controllo di attività:
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.GeneratedMethodAccessor52.invoke(Unknown
Source)\n\tsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\t
","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
Nei log del pod delle release di Apigee hybrid >= 1.4.0 vedrai il seguente Cannot build a cluster without contact points errore:apigee-synchronizer
{"timestamp":"1621575636434","level":"ERROR","thread":"main","logger":"KERNEL.DEPLOYMENT","message":
"ServiceDeployer.deploy() : Got a life cycle exception while starting service [SyncService, Cannot
build a cluster without contact points] : {}","context":"apigee-service-
logs","exception":"java.lang.IllegalArgumentException: Cannot build a cluster without contact
points\n\tat com.datastax.driver.core.Cluster.checkNotEmpty(Cluster.java:134)\n\tat
com.datastax.driver.core.Cluster.<init>(Cluster.java:127)\n\tat
com.datastax.driver.core.Cluster.buildFrom(Cluster.java:193)\n\tat
com.datastax.driver.core.Cluster$Builder.build(Cluster.java:1350)\n\tat
io.apigee.persistence.PersistenceContext.newCluster(PersistenceContext.java:214)\n\tat
io.apigee.persistence.PersistenceContext.<init>(PersistenceContext.java:48)\n\tat
io.apigee.persistence.ApplicationContext.<init>(ApplicationContext.java:19)\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceImpl.<init>(RuntimeConfigServiceImpl.java:75)
\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceFactory.newInstance(RuntimeConfigServiceFactory.
java:99)\n\tat
io.apigee.common.service.AbstractServiceFactory.initializeService(AbstractServiceFactory.java:301)\n
\tat
...","severity":"ERROR","class":"com.apigee.kernel.service.deployment.ServiceDeployer","method":"sta
rtService"}
Nei log del pod apigee-mart delle release ibride di Apigee >= 1.4.0 vedrai i seguenti errori di mancata risposta del test di attività:
{"timestamp":"1621576757592","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.NativeMethodAccessorImpl.invoke0(Native
Method)\n\tsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\t","conte
xt":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621576757593","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}Informazioni sull'errore Nessun pod di runtime attivo
Nella release Apigee hybrid 1.4.0, la funzionalità di probe di attività è stata aggiunta ai pod apigee-runtime e apigee-mart per controllare lo stato dei pod Cassandra. Se tutti i pod Cassandra non sono disponibili, i probe di attività dei pod apigee-runtime e apigee-mart non andranno a buon fine. Di conseguenza, i pod
apigee-runtime e apigee-mart passeranno allo stato
CrashLoopBackOff , causando il fallimento dei deployment dei proxy API con l'avviso
No active runtime pods.
Anche il pod apigee-synchronizer passerà allo stato CrashLoopBackOff
a causa della mancata disponibilità dei pod Cassandra.
Cause possibili
Ecco alcune possibili cause di questo errore:
| Causa | Descrizione |
|---|---|
| I pod Cassandra non sono attivi | I pod Cassandra non sono attivi; pertanto, i pod apigee-runtime non potranno comunicare con il database Cassandra. |
| Replica Cassandra configurata con un solo pod | Avere un solo pod Cassandra potrebbe diventare un single point of failure. |
Causa: i pod Cassandra non sono attivi
Durante il processo di implementazione del proxy API, i pod apigee-runtime si connettono al database Cassandra per recuperare le risorse, ad esempio le mappe di valori chiave (KVM) e le cache, definite nel proxy API. Se non sono in esecuzione pod Cassandra, i pod apigee-runtime non potranno connettersi al database Cassandra. Ciò comporta il fallimento del deployment del proxy API.
Diagnosi
- Elenca i pod Cassandra:
kubectl -n apigee get pods -l app=apigee-cassandra
Esempio di output 1:
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 0/1 Pending 0 9m23s
Esempio di output 2:
NAME READY STATUS RESTARTS AGE apigee-cassandra-0 0/1 CrashLoopBackoff 0 10m
- Verifica lo stato di ogni pod Cassandra. Lo stato di tutti i pod Cassandra deve essere in stato
Running. Se uno dei pod Cassandra è in uno stato diverso, potrebbe essere la causa del problema. Per risolvere il problema, procedi nel seguente modo:
Risoluzione
- Se uno dei pod Cassandra è nello stato
Pending, consulta I pod Cassandra sono bloccati nello stato Pending (In attesa) per risolvere il problema. - Se uno dei pod Cassandra è in stato
CrashLoopBackoff, consulta I pod Cassandra sono bloccati nello stato CrashLoopBackoff per risolvere il problema.Esempio di output:
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Causa: replica Cassandra configurata con un solo pod
Se il conteggio delle repliche di Cassandra è configurato su 1, nel runtime sarà disponibile un solo pod Cassandra. Di conseguenza, i pod apigee-runtime potrebbero riscontrare problemi di connettività se il pod Cassandra diventa non disponibile per un determinato periodo di tempo.
Diagnosi
- Ottieni l'insieme stateful Cassandra e controlla il numero di repliche corrente:
kubectl -n apigee get statefulsets -l app=apigee-cassandra
Esempio di output:
NAME READY AGE apigee-cassandra-default 1/1 21m
- Se il numero di repliche è configurato su 1, segui questi passaggi per aumentarlo a un numero superiore.
Risoluzione
I deployment di Apigee hybrid non di produzione potrebbero avere il numero di repliche Cassandra impostato su 1. Se l'alta disponibilità di Cassandra è importante nei deployment non in produzione, aumenta il numero di repliche a 3 per risolvere il problema.
Per risolvere il problema, svolgi i seguenti passaggi:
- Aggiorna il file
overrides.yamle imposta il conteggio delle repliche Cassandra su 3:cassandra: replicaCount: 3
Per informazioni sulla configurazione di Cassandra, consulta Riferimento per le proprietà di configurazione.
- Applica la configurazione precedente utilizzando Helm:
Prova:
helm upgrade datastore apigee-datastore/ \ --install \ --namespace APIGEE_NAMESPACE \ --atomic \ -f OVERRIDES_FILE \ --dry-run
Installa il grafico Helm
helm upgrade datastore apigee-datastore/ \ --install \ --namespace APIGEE_NAMESPACE \ --atomic \ -f OVERRIDES_FILE
- Ottieni l'insieme stateful Cassandra e controlla il numero di repliche corrente:
kubectl -n get statefulsets -l app=apigee-cassandra
Esempio di output:
NAME READY AGE apigee-cassandra-default 3/3 27m
- Ottieni i pod Cassandra e controlla il conteggio delle istanze correnti. Se non tutti i pod sono pronti e
sono nello stato
Running, attendi che i nuovi pod Cassandra vengano creati e attivati:kubectl -n get pods -l app=apigee-cassandra
Esempio di output:
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 1/1 Running 0 29m apigee-cassandra-default-1 1/1 Running 0 21m apigee-cassandra-default-2 1/1 Running 0 19m
Esempio di output:
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Deve raccogliere informazioni di diagnostica
Se il problema persiste anche dopo aver seguito le istruzioni riportate sopra, raccogli le seguenti informazioni di diagnostica, quindi contatta l'assistenza clienti Google Cloud.
- ID progetto Google Cloud
- Apigee hybrid/organizzazione Apigee
- Per Apigee hybrid:
overrides.yaml, che maschera le informazioni sensibili - Stato del pod Kubernetes in tutti gli spazi dei nomi:
kubectl get pods -A > kubectl-pod-status`date +%Y.%m.%d_%H.%M.%S`.txt
- Dump di informazioni sul cluster Kubernetes:
# generate kubernetes cluster-info dump kubectl cluster-info dump -A --output-directory=/tmp/kubectl-cluster-info-dump # zip kubernetes cluster-info dump zip -r kubectl-cluster-info-dump`date +%Y.%m.%d_%H.%M.%S`.zip /tmp/kubectl-cluster-info-dump/*
Riferimenti
- Scalabilità orizzontale di Cassandra
- Introspezione e debug delle applicazioni Kubernetes
- Scheda di riferimento di kubectl