Sie lesen gerade die Dokumentation zu Apigee und Apigee Hybrid.
Apigee Edge-Dokumentation aufrufen.
Symptome
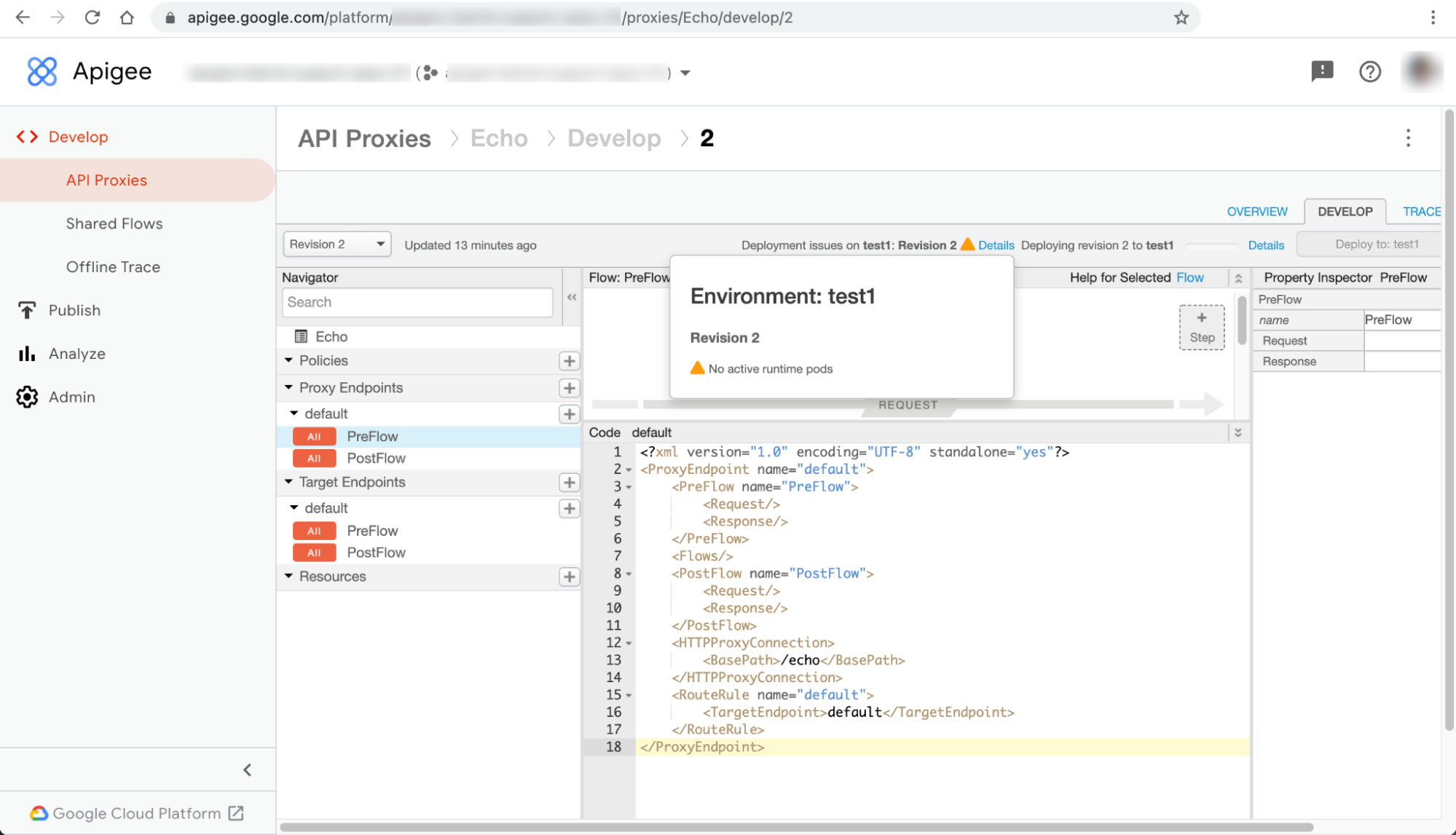
Bereitstellungen von API-Proxys schlagen mit der Warnung Keine aktiven Laufzeit-Pods in der Apigee Hybrid-UI fehl.
Fehlermeldungen
Die Warnung Keine aktiven Laufzeit-Pods wird im Dialogfeld Details neben der Fehlermeldung Probleme bei der Bereitstellung in ENVIRONMENT: REVISION_NUMBER angezeigt.
Dieses Problem kann in unterschiedlicher Form als Fehler auf anderen Ressourcenseiten der Benutzeroberfläche auftreten. Im Folgenden sind einige Beispiele für solche Fehlermeldungen aufgeführt:
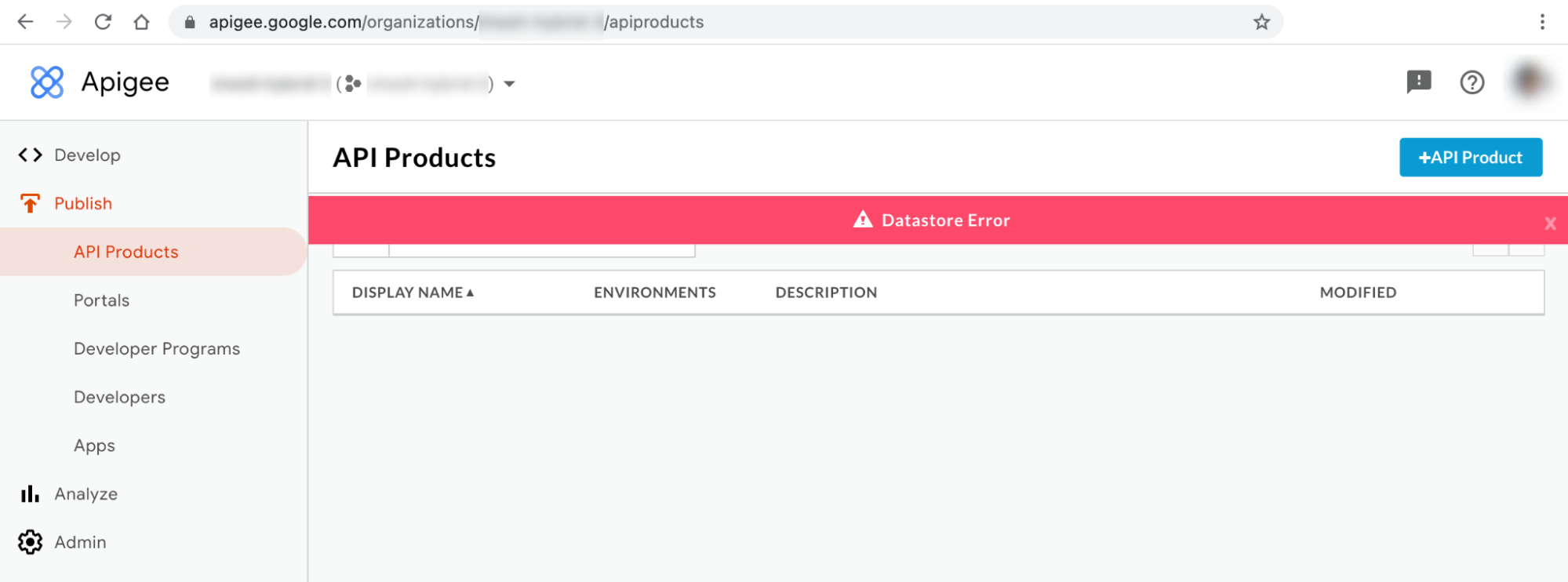
Hybrid-UI-Fehlermeldung Nr. 1: Datastore-Fehler
Möglicherweise beobachten Sie den Datastore-Fehler auf den Seiten API-Produkte und Anwendungen der Hybrid-UI, der im Folgenden dargestellt ist:
Hybrid-UI-Fehlermeldung Nr. 2: Interner Serverfehler
Möglicherweise wird Interner Serverfehler auf der Seite Entwickler der UI angezeigt:

Kubectl-Befehlsausgabe
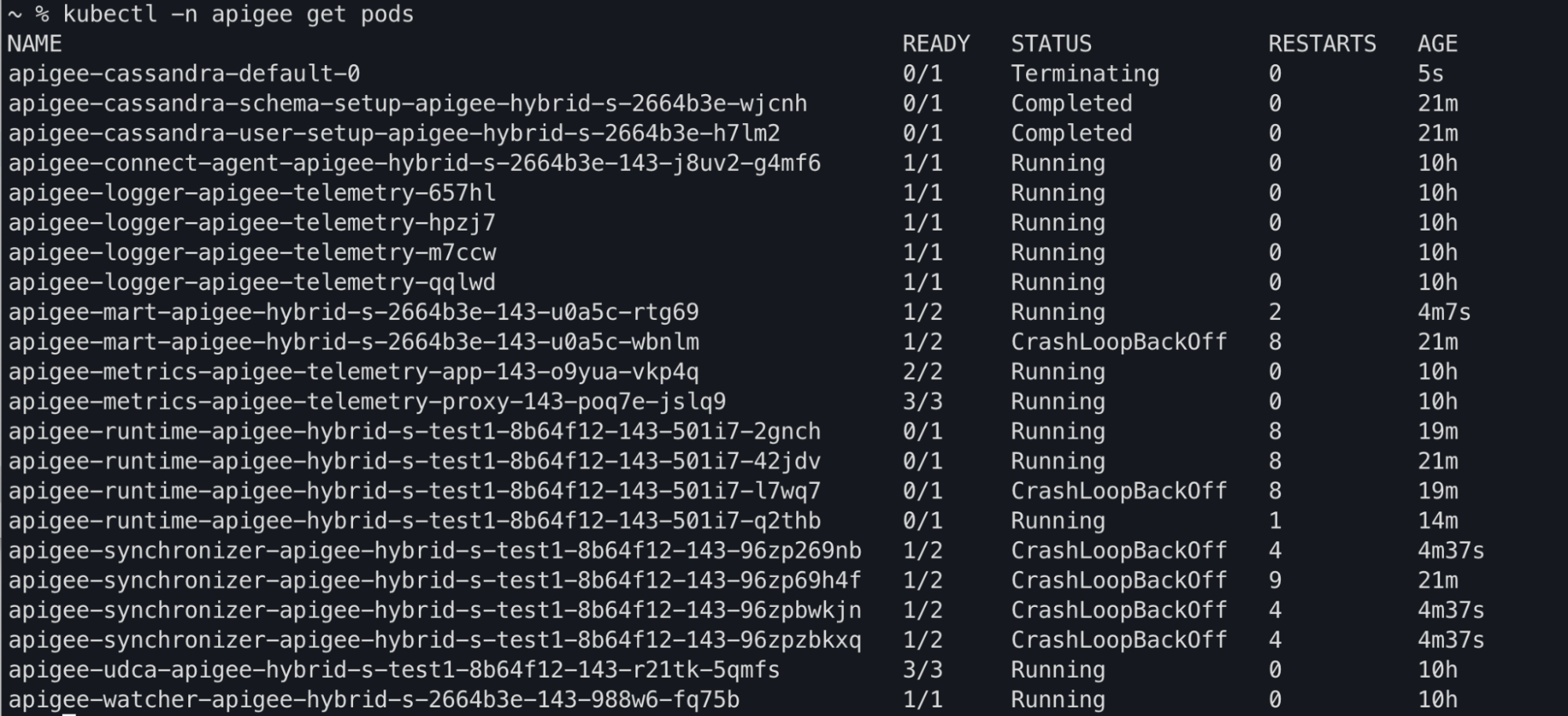
Sie können möglicherweise beobachten, wie sich die Pod-Status apiege-mart, apigee-runtime und apigee-
synchronizer in der Befehlsausgabe von kubectl get pods in CrashLoopBackOff ändern:
Fehlermeldungen im Komponentenlog
In den apigee-runtime-Pod-Logs in Apigee Hybrid-Releases >= 1.4.0 werden folgende Fehler bei der Aktivitätsprüfung angezeigt:
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.GeneratedMethodAccessor52.invoke(Unknown
Source)\n\tsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\t
","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621575431454","level":"ERROR","thread":"qtp365724939-205","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
Sie sehen den folgenden Cannot build a cluster without contact points -Fehler in apigee-synchronizer-Pod-Logs in Apigee Hybrid-Releases >= 1.4.0:
{"timestamp":"1621575636434","level":"ERROR","thread":"main","logger":"KERNEL.DEPLOYMENT","message":
"ServiceDeployer.deploy() : Got a life cycle exception while starting service [SyncService, Cannot
build a cluster without contact points] : {}","context":"apigee-service-
logs","exception":"java.lang.IllegalArgumentException: Cannot build a cluster without contact
points\n\tat com.datastax.driver.core.Cluster.checkNotEmpty(Cluster.java:134)\n\tat
com.datastax.driver.core.Cluster.<init>(Cluster.java:127)\n\tat
com.datastax.driver.core.Cluster.buildFrom(Cluster.java:193)\n\tat
com.datastax.driver.core.Cluster$Builder.build(Cluster.java:1350)\n\tat
io.apigee.persistence.PersistenceContext.newCluster(PersistenceContext.java:214)\n\tat
io.apigee.persistence.PersistenceContext.<init>(PersistenceContext.java:48)\n\tat
io.apigee.persistence.ApplicationContext.<init>(ApplicationContext.java:19)\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceImpl.<init>(RuntimeConfigServiceImpl.java:75)
\n\tat
io.apigee.runtimeconfig.service.RuntimeConfigServiceFactory.newInstance(RuntimeConfigServiceFactory.
java:99)\n\tat
io.apigee.common.service.AbstractServiceFactory.initializeService(AbstractServiceFactory.java:301)\n
\tat
...","severity":"ERROR","class":"com.apigee.kernel.service.deployment.ServiceDeployer","method":"sta
rtService"}
In den apigee-mart-Pod-Logs in Apigee Hybrid-Releases >= 1.4.0 werden folgende Fehler bei der Aktivitätsprüfung angezeigt:
{"timestamp":"1621576757592","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Error occurred : probe failed Probe cps-datastore-
connectivity-liveliness-probe failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts =
[]}\n\n\tcom.apigee.probe.ProbeAPI.getResponse(ProbeAPI.java:66)\n\tcom.apigee.probe.ProbeAPI.getLiv
eStatus(ProbeAPI.java:55)\n\tsun.reflect.NativeMethodAccessorImpl.invoke0(Native
Method)\n\tsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)\n\t","conte
xt":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}
{"timestamp":"1621576757593","level":"ERROR","thread":"qtp991916558-144","mdc":{"targetpath":"/v1/pr
obes/live"},"logger":"REST","message":"Returning error response : ErrorResponse{errorCode =
probe.ProbeRunError, errorMessage = probe failed Probe cps-datastore-connectivity-liveliness-probe
failed due to com.apigee.probe.model.ProbeFailedException{ code =
cps.common.datastoreConnectionNotHealthy, message = Datastore connection not healthy, associated
contexts = []}}","context":"apigee-service-
logs","severity":"ERROR","class":"com.apigee.rest.framework.container.ExceptionMapper","method":"toR
esponse"}Informationen zum Fehler „Keine aktiven Laufzeit-Pods“
In der Version Apigee Hybrid 1.4.0 wurde den Pods apigee-runtime und apigee-mart die Aktivitätsprüfung auf den Status der Cassandra-Pods hinzugefügt. Wenn keine Cassandra-Pods mehr verfügbar sind, schlagen die Aktivitätsprüfungen der Pods apigee-runtime und apigee-mart fehl. Die Pods apigee-runtime und apigee-mart wechseln in diesem Fall in den Status CrashLoopBackOff , wodurch die Bereitstellung von API-Proxys mit der Warnung No active runtime pods fehlschlägt.
Außerdem wechselt der Pod apigee-synchronizer in den Status CrashLoopBackOff , da keine Cassandra-Pods verfügbar sind.
Mögliche Ursachen
Hier finden Sie einige mögliche Ursachen für diesen Fehler:
| Ursache | Beschreibung |
|---|---|
| Cassandra-Pods sind ausgefallen | Cassandra-Pods sind ausgefallen, sodass apigee-runtime-Pods nicht mit der Cassandra-Datenbank kommunizieren können. |
| Cassandra-Replikat ist mit nur einem Pod konfiguriert | Das Vorhandensein von nur einem Cassandra-Pod könnte zu einem Single Point of Failure werden. |
Ursache: Cassandra-Pods sind ausgefallen
Für die API-Proxy-Bereitstellung stellen die apigee-runtime-Pods eine Verbindung zur Cassandra-Datenbank her, um Ressourcen wie Schlüssel/Wert-Paar-Zuordnungen (Key Value Maps, KVMs) und Caches abzurufen, die im API-Proxy definiert sind. Wenn keine Cassandra-Pods ausgeführt werden, können apigee-runtime-Pods keine Verbindung zur Cassandra-Datenbank herstellen. Dies führt dann zu einem Fehler bei der API-Proxy-Bereitstellung.
Diagnose
- Listen Sie die Cassandra-Pods auf:
kubectl -n apigee get pods -l app=apigee-cassandra
Beispielausgabe 1:
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 0/1 Pending 0 9m23s
Beispielausgabe 2:
NAME READY STATUS RESTARTS AGE apigee-cassandra-0 0/1 CrashLoopBackoff 0 10m
- Prüfen Sie den Status der einzelnen Cassandra-Pods. Alle Cassandra-Pods sollten den Status
Runninghaben. Befindet sich ein Cassandra-Pod in einem anderen Status, kann dies der Grund für das Problem sein. Führen Sie zur Behebung dieses Problems die folgenden Schritte aus:
Lösung
- Wenn einer der Cassandra-Pods den Status
Pendinghat, erhalten Sie unter Cassandra-Pods verbleiben im Status "Ausstehend" weiter Informationen, um das Problem zu beheben. - Wenn einer der Cassandra-Pods den Status
CrashLoopBackoffhat, erhalten Sie unter Cassandra-Pods verbleiben im CrashLoopBackoff-Status weitere Informationen, um das Problem zu beheben.Beispielausgabe:
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Ursache: Cassandra-Replikat ist mit nur einem Pod konfiguriert
Wenn die Cassandra-Replikatanzahl auf eins konfiguriert ist, ist nur ein Cassandra-Pod in der Laufzeit verfügbar. Daher können bei apigee-runtime-Pods Verbindungsprobleme auftreten, wenn dieser Cassandra-Pod für einen bestimmten Zeitraum nicht mehr verfügbar ist.
Diagnose
- Rufen Sie das zustandsorientierte Set von Cassandra ab und prüfen Sie die aktuelle Replikatanzahl:
kubectl -n apigee get statefulsets -l app=apigee-cassandra
Beispielausgabe:
NAME READY AGE apigee-cassandra-default 1/1 21m
- Wenn für die Replikatanzahl 1 konfiguriert ist, führen Sie die folgenden Schritte aus, um die Anzahl zu erhöhen.
Lösung
Für Nicht-Produktionsbereitstellungen von Apigee Hybrid kann die Cassandra-Replikatanzahl auf 1 gesetzt sein. Wenn eine hohe Verfügbarkeit von Cassandra in Nicht-Produktionsbereitstellungen wichtig ist, erhöhen Sie die Replikatanzahl auf 3, um dieses Problem zu beheben.
Führen Sie zur Behebung dieses Problems die folgenden Schritte aus:
- Aktualisieren Sie die Datei
overrides.yamlund legen Sie die Anzahl der Cassandra-Replikate auf 3 fest:cassandra: replicaCount: 3
Informationen zu Cassandra-Konfigurationen finden Sie in der Referenz zu Konfigurationsattributen.
- Wenden Sie die obige Konfiguration mit Helm an:
Probelauf:
helm upgrade datastore apigee-datastore/ \ --install \ --namespace APIGEE_NAMESPACE \ --atomic \ -f OVERRIDES_FILE \ --dry-run
Helm-Diagramm installieren
helm upgrade datastore apigee-datastore/ \ --install \ --namespace APIGEE_NAMESPACE \ --atomic \ -f OVERRIDES_FILE
- Rufen Sie das zustandsorientierte Set von Cassandra ab und prüfen Sie die aktuelle Replikatanzahl:
kubectl -n get statefulsets -l app=apigee-cassandra
Beispielausgabe:
NAME READY AGE apigee-cassandra-default 3/3 27m
- Rufen Sie die Cassandra-Pods ab und prüfen Sie die aktuelle Instanzanzahl. Wenn die Pods nicht bereit sind und den Status
Runninghaben, warten Sie, bis die neuen Cassandra-Pods erstellt und aktiviert sind:kubectl -n get pods -l app=apigee-cassandra
Beispielausgabe:
NAME READY STATUS RESTARTS AGE apigee-cassandra-default-0 1/1 Running 0 29m apigee-cassandra-default-1 1/1 Running 0 21m apigee-cassandra-default-2 1/1 Running 0 19m
Beispielausgabe:
kubectl -n apigee get pods -l app=apigee-runtime NAME READY STATUS RESTARTS AGE apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-2gnch 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-42jdv 1/1 Running 13 45m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-l7wq7 1/1 Running 13 43m apigee-runtime-apigee-hybrid-s-test1-8b64f12-143-501i7-q2thb 1/1 Running 8 38m
kubectl -n apigee get pods -l app=apigee-mart NAME READY STATUS RESTARTS AGE apigee-mart-apigee-hybrid-s-2664b3e-143-u0a5c-rtg69 2/2 Running 8 28m
kubectl -n apigee get pods -l app=apigee-synchronizer NAME READY STATUS RESTARTS AGE apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp269nb 2/2 Running 10 29m apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zp2w2jp 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpkfkvq 2/2 Running 0 4m40s apigee-synchronizer-apigee-hybrid-s-test1-8b64f12-143-96zpxmzhn 2/2 Running 0 4m40s
Erfassen von Diagnoseinformationen erforderlich
Wenn das Problem auch nach Befolgen der obigen Anweisungen weiterhin besteht, sammeln Sie die folgenden Diagnoseinformationen und wenden Sie sich dann an Google Cloud Customer Care:
- Google Cloud-Projekt-ID
- Apigee Hybrid-/Apigee-Organisation
- Für Apigee Hybrid: die Datei
overrides.yamlzur Maskierung vertraulicher Informationen - Kubernetes-Pod-Status in allen Namespaces:
kubectl get pods -A > kubectl-pod-status`date +%Y.%m.%d_%H.%M.%S`.txt
- cluster-info-Dump von Kubernetes:
# generate kubernetes cluster-info dump kubectl cluster-info dump -A --output-directory=/tmp/kubectl-cluster-info-dump # zip kubernetes cluster-info dump zip -r kubectl-cluster-info-dump`date +%Y.%m.%d_%H.%M.%S`.zip /tmp/kubectl-cluster-info-dump/*
Verweise
- Horizontale Cassandra-Skalierung
- Kubernetes – Anwendungsintrospektion und Debugging
- kubectl auf einen Blick