Esta página se aplica à Apigee e à Apigee híbrida.
Confira a documentação da
Apigee Edge.

O que esse painel informa?
O painel de análise de latência pode alertar sobre problemas de latência que seus proxies de API possam estar enfrentando. Ele exibe as medidas de latência com precisão de minuto, destacando os valores de mediana, 95º e 99º percentil.
O valor de mediana indica o ponto em que metade do tráfego está sofrendo latência inferior ao valor e a metade do tráfego está passando por uma latência maior do que esse valor. Por exemplo, se a latência de tempo médio de resposta do proxy da API selecionada for 62 ms, isso significa que metade das respostas desse proxy de API leva menos de 62 ms. Isso também significa que metade das respostas desse proxy de API leva mais de 62 ms.
Os valores de 95º e 99º percentil informam o ponto em que 95% e 99% do tráfego está passando por uma latência menor que esses valores. Ou, mais importante, pode apontar o comportamento fora do esperado, informando que 5% e 1% do tráfego estão enfrentando valores de latência fora do intervalo.
Painel "Análise de latência"
Para acessar o painel "Análise de latência":
No console Google Cloud , acesse a página Analytics > Métricas de API > Análise de latência.
A visualização Análise de latência é mostrada:
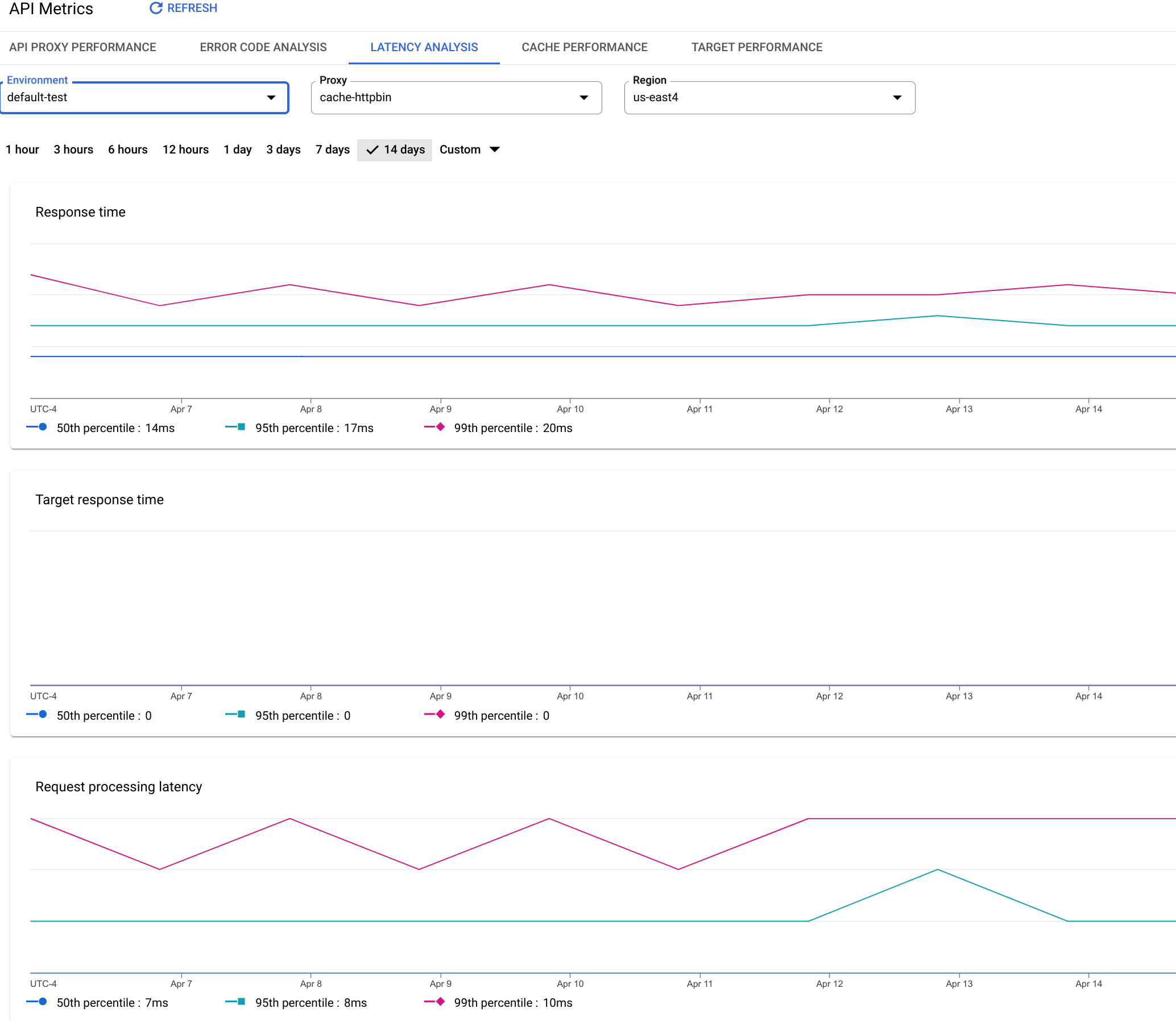
O que esse painel mede?
Veja também este artigo interessante no site da comunidade da Apigee (em inglês): Quando o tempo total de resposta total pode ser menor que o tempo médio de resposta?
| Métrica | Descrição |
|---|---|
| Tempo de resposta | Número total de milissegundos para responder a uma chamada. Esse tempo inclui a sobrecarga do proxy da API Apigee e o horário do servidor de destino. |
| Tempo de resposta do destino | Número de milissegundos que o servidor de destino levou para responder a uma chamada. Esse número informa o comportamento dos seus próprios servidores. |
| Latência no processamento da solicitação |
Número de milissegundos a partir do momento em que uma chamada chega ao proxy de API selecionado até o momento em que a Apigee envia a chamada para o servidor de destino. As latências de solicitação e resposta são somadas para calcular a sobrecarga final que o proxy da API adicionou à chamada. |
| Latência de processamento de respostas |
Número de milésimos de segundo a partir do momento em que o proxy da API recebe a resposta do servidor de destino até o momento em que a Apigee envia a resposta para o autor da chamada original. As latências de solicitação e resposta são somadas para calcular a sobrecarga final que o proxy da API adicionou à chamada. |